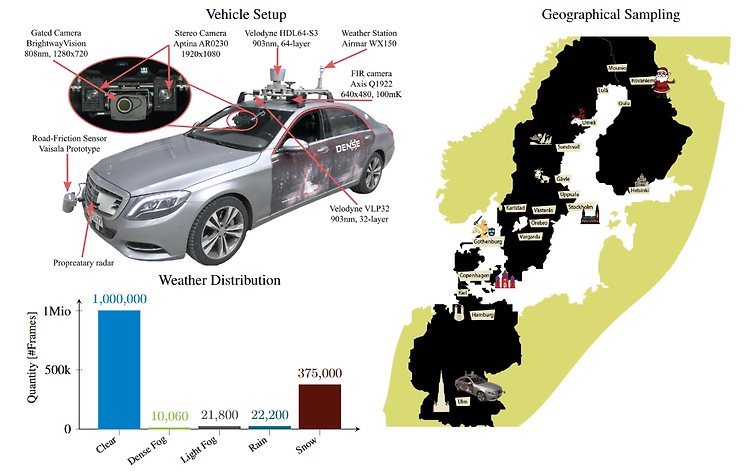
Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather Introduction & Related Works The fusion of multimodal sensor streams, such as camera, lidar, and radar measurements, plays a critical role in object detection for autonomous vehicles, which base their decision making on these inputs. While existing methods exploit redundant information in good environm..