Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather
Introduction & Related Works
The fusion of multimodal sensor streams, such as camera, lidar, and radar measurements, plays a critical role in object detection for autonomous vehicles, which base their decision making on these inputs. While existing methods exploit redundant information in good environmental conditions, they fail in adverse weather where the sensory streams can be asymmetrically distort.
기존 sensorfusion 방법들이 adverse weather에서 약하다는 뜻. 너무 당연한 얘기이다. 그래서 각종 데이터셋도 만들고, 방법론도 제안한다는 얘기이다.
The network architecture of these approaches is designed with the assumption that the data streams are consistent and redundant, i.e. an object appearing in one sensory stream also appears in the other. However, in harsh weather conditions, such as fog, rain, snow, or extreme lighting condition, including low-light or low-reflectance objects, multimodal sensor configurations can fail asymmetrically.
기존 방법들은 LiDAR에서 나오는 것이면 image에서도 나올 것이라는 가정하에 architecture를 제안했다. 하지만 실제 harsh weather condition에서는 LiDAR에서만 물체가 감지되지 않거나, image에서만 감지되지 않거나 할 수 있다는 주장이다. 즉, 서로 보완적인 센서로 사용할 수 있다는 의미.
For example, conventional RGB cameras provide unreliable noisy measurements in low-light scene areas, while scanning lidar sensors provide reliable depth using active illumination. In rain and snow, small particles affect the color image and lidar depth estimates equally through backscatter. Adversely, in foggy or snowy conditions, state-of-the-art pulsed lidar systems are restricted to less than 20 m range due to backscatter, see Figure 3. While relying on lidar measurements might be a solution for night driving, it is not for adverse weather conditions.
low light에서는 LiDAR가 효과적, foggy/snowy에서는 LiDAR가 치명적, rain/snow particle에 대해서는 image LiDAR 모두가 치명적인 영향을 받는다는 것을 언급한다.
we propose an adaptive single-shot deep fusion architecture which exchanges features in intertwined feature extractor blocks. This deep early fusion is steered by measured entropy. The proposed adaptive fusion allows us to learn models that generalize across scenarios.
이를 해결하기 위해서 방법론 적으로는 feature extractor block을 intertwine한 구조로 만든다고 한다. Fusion 자체는 entropy 측정으로 행한다고 한다. 그리고 이게 일반화가 잘된다는 얘기.
관련있는 연구로는 다음과 같다.
Detection in Adverse Weather Conditions : 기존 연구에서는 clean 사오항만 고려하고 있었다는 언급. 그래서 이번에는 adverse weather에서 object detection 잘해보겠다고 제안한다.
Data Preprocessing in Adverse Weather : Fog의 경우 거리에 따른 contrast와 color loss가 있다고 언급. scene prior와 latent clear image에 의존하여 fog를 제거한다고 한다. ill posed problem이라고 한다.
Domain Adaptation : domain adaptation을 통해 adverse weather를 극복하려고 할 수도 있다. 하지만 weather representation은 상당히 애매한 영역이라서, label까지 다시 표현하려고 하면 상당히 머리 아프다.
Multisensor Fusion : 기존 연구들이 있긴한데, 대부분 adverse weather와 같은 assymetric measurement distortion이 있는 환경에서 낮은 성능을 기록했다고 한다.
Multimodal Adverse Weather Dataset
2D, 3D object detection을 위한 dataset을 구성했다고 한다. 주요 목적은 validation인 듯 하다.
The individual weather conditions result in asymmetrical perturbations of various sensor technologies, leading to asymmetric degradation, i.e. instead of all sensor outputs being affected uniformly by a deteriorating environmental condition, some sensors degrade more than others, see Figure 3.
모든 센서가 비슷한 정도로 오염되는 게 아니라 각자 다른 수준으로 오염된다고 한다. 그런데 이건 당연한게 image랑 LiDAR는 표현 방식이 다르기에, distortion 결과도 다를 수밖에 없다...
Meanwhile, active scanning sensors as lidar and radar are less affected by ambient light changes due to active illumination and a narrow bandpass on the detector side. On the other hand, active lidar sensors are highly degraded by scattering media as fog, snow or rain, limiting the maximal perceivable distance at fog densities below 50 m to 25 m, see Figure 3.
LiDAR 등 빛을 쏘는 경우 day-night에는 영향을 덜 받는다. 하지만 weather와 같은 visibility distance에 영향을 주는 경우에 취약해진다. Camera도 이 때 성능이 나빠지지만 상대적으로는 나은 수준. Radar는 거의 영향을 안받는다. 하지만 잘 쓰지 않아서... Gated image도 날씨에는 더 나은 성능을 보인다고 한다.
즉, 센서마다 나은 성능을 보이는 상황이 다르다.
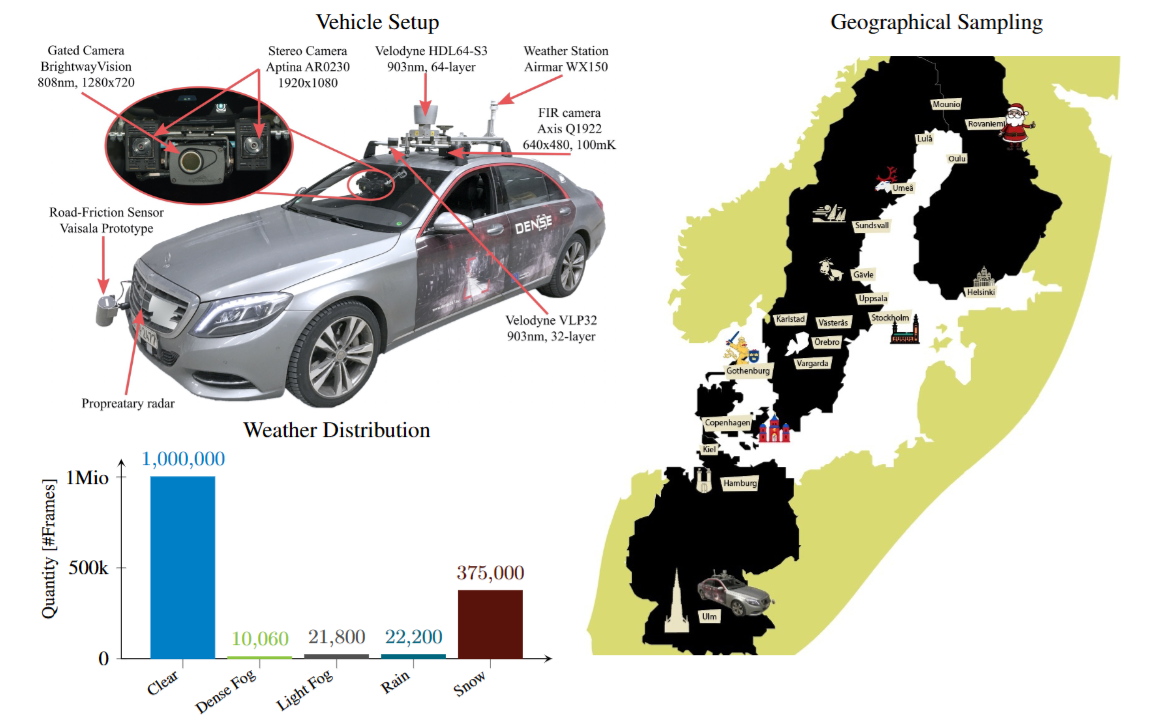
Multimodal Sensor Setup
Stereo Camera, Gated camera, Radar, Lidar, FIR camera, Environmental Sensors를 사용한다. 처음 보는 센서들을 좀 정리하고 가려고 한다.
처음 보는 NIR Gated camera 는 laser를 발사하고, 몇 초 후 이를 다시 수령하는 식으로 운용된다. NIR을 사용하면 backscattering effect가 다소 줄어든다고. 이게 장점인지 단점인지는 모르겠다.
Furthermore, the high imager speed enables to capture multiple overlapping slices with different range-intensity profiles encoding extractable depth information in between multiple slices [23]. Following [23], we capture 3 broad slices for depth estimation and additionally 3-4 narrow slices together with their passive correspondence at a system sampling rate of 10 Hz.
이것은 뭐라는 것인지 모르겠다.
FIR camera는 원적외선 카메라로, 열감지 이미지를 만들어낸다.
Environmental Sensors는 온도, 바람 속도, 습도 등을 측정한다.
Methods : Adaptive Deep Fusion
Adaptive Multimodal Single-Shot Fusion
image는 RGB style을 그대로 활용. LiDAR, Radar는 BEV view로 활용한다. 이 둘은 형상이 너무 달라서 early fusion이 불가능하다고 언급된다. LiDAR encoder는 depth, height, intensity를 받아서 processing을 한다. Radar의 경우 image와 orthogonal하게 데이터를 수집한다고 가정한다. Gated image는 homography mapping으로 RGB image와 동일한 plane으로 놓는다. 그 후 position & intensity dependent한 fusion을 위한 correspondence를 찾는다. 여기서 correspondence가 없다면 0 value를 넣는다.
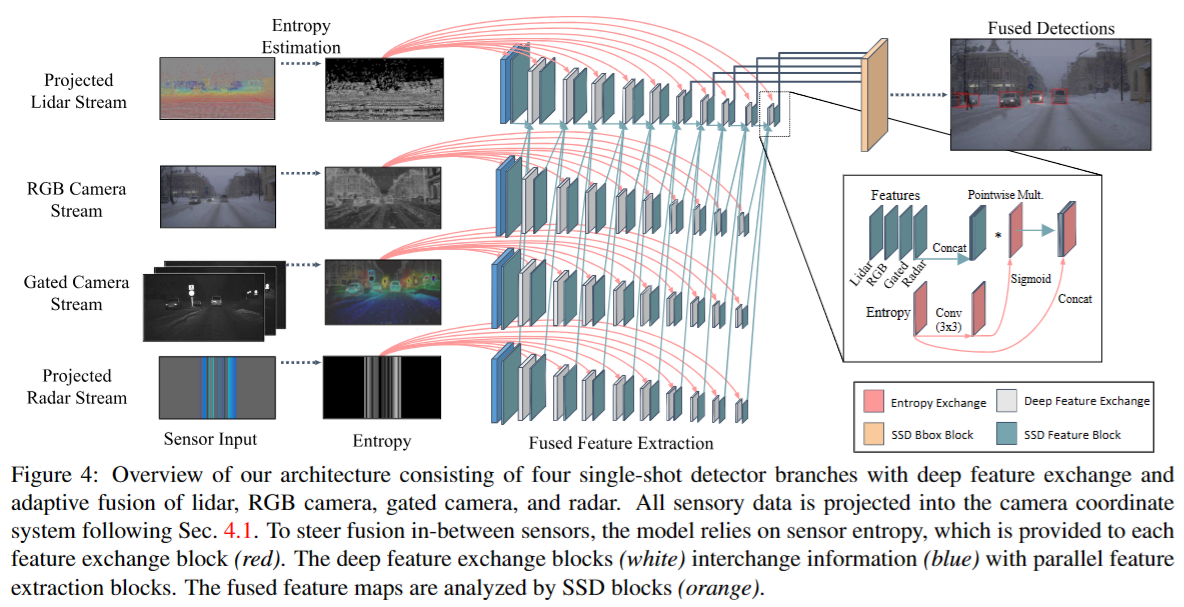
각 feature를 processing하는 방법은 위와 같다. 각 data별로 entropy를 추정하고, SSD block을 두어 processing한다. 디테일한 processing 구조는 위의 오른쪽과 같이 각 data type을 concat하고 entropy에 sigmoid를 가한 것과 pointwise multiply하고, 그 후 다시 concat하는 방식으로 구성된다. 여기서 entropy가 높은 곳 위주로 feature extraction한다.
Entropy-steered Fusion
image space에서의 entropy는 다음과 같이 기술된다.
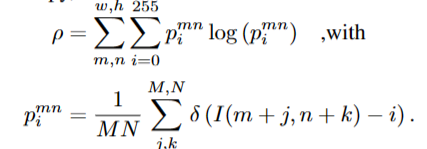
이 과정은 16x16 window상에서의 convolution like operation을 통해서 얻을 수 있다. 그 결과는 아래와 같다.
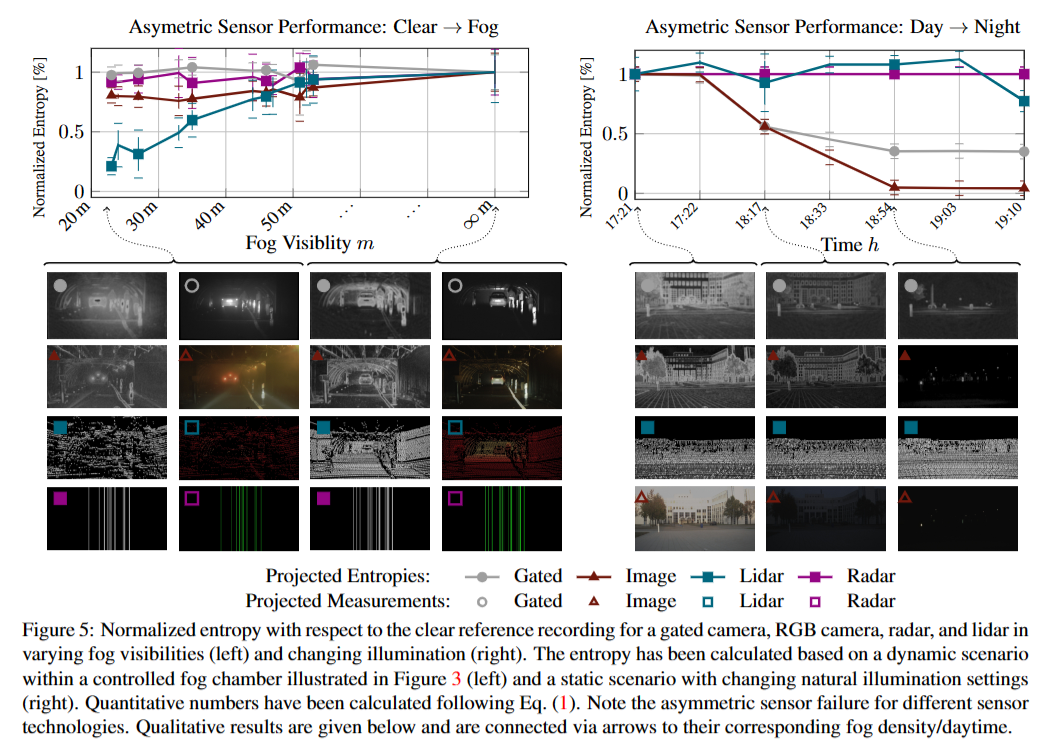
각 센서의 효과와 장단점에 대해서 다음과 같이 기술한다.
The passive RGB camera and lidar suffer from backscatter and attenuation with decreasing fog visibilities, while the gated camera suppresses backscatter through gating. Radar measurements are also not substantially degraded in fog.
RGB camera와 lidar는 backscatter와 attenuation에 영향을 많이 받는다. Gated image는 이에 강건하다.
The right scenario in Figure 5 shows a static outdoor scene under varying ambient lighting. In this scenario, active lidar and radar are not affected by changes in ambient illumination. For the gated camera, the ambient illumination disappears, leaving only the actively illuminated areas, while the passive RGB camera degenerates with decreasing ambient light.
LiDAR와 radar는 illumination에 큰 영향을 받지 않는다. Gated camera의 경우 어두워지면 ambient light(반사되어 돌아오는 빛)에 의한 효과는 사라지지만 active illumination(카메라 자체가 내뿜는 빛)만 남는다. 주변광은 사라진다. RGB 카메라는 ambient light가 사라지면 그냥 성능이 떨어진다. 이러한 training 과정은 clean data를 통해서만 수행된다.
Loss Functions and Training Details
각 SSD module에서 나온 anchor box의 class probability는 cross entropy loss를 통해 학습된다.
matching threshold 0.5를 넘는 anchor box는 huber loss를 통해 학습된다.
hard example mining을 통해 negative box가 positive box의 5배까지만 존재할 수 있게한다.
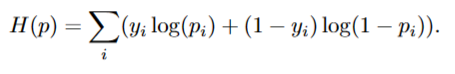
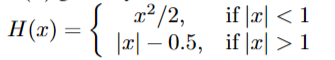
Experiments
harsh condition일 수록 더 나은 성능을 보이는 것을 알 수 있다. 최고 성능이 아니더라도 대체로 최고 성능인 method에 비해 밀리지는 않는 모습을 보인다.
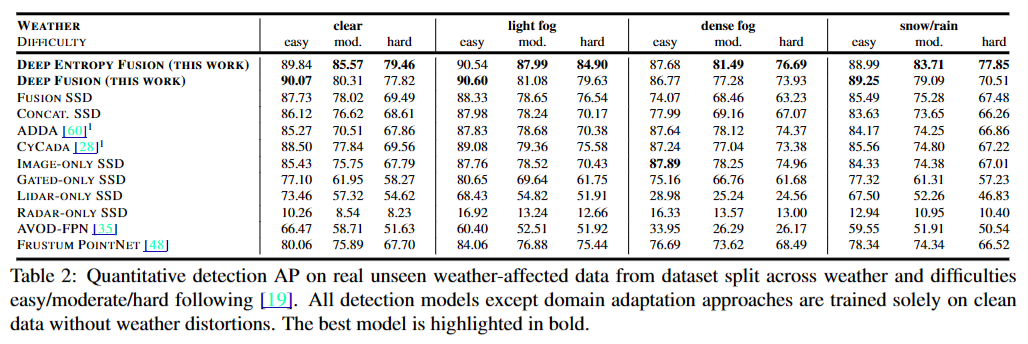
Two-stage methods, such as Frustum PointNet [48], drop quickly. However, they asymptotically achieve higher results compared to AVOD, because the statistical priors learned for the first stage are based on Image-only SSD that limits its performance to image-domain priors. AVOD is limited by several assumptions that hold for clear weather, such as the importance sampling of boxes filled with lidar data during training, achieving the lowest fusion performance overall
다른 method의 성능하락에 대한 이유
severe condition에서 다른 method에 비해 성능이 덜 떨어진 이유가 무엇일까? 다른 method를 확인해봐야 확실하게 감각이 오겠지만, 아무래도 각 data style에서 uncertainty가 높은 pixel에 대해 학습을 여러번 시도한 것이 효과적이지 않았을까 싶다. 다만 현실적으로 다른 dataset에는 없는 sensor data가 사용되어서 광범위하게 사용할 수 있는 method는 아닌 듯 하다. 그래도 motivation은 줄 수 있을 듯.