반응형
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
주요 업적 :
- atrous convolution
- atrous spatial pyramid pooling (ASPP)
- fully connected Conditional Random Field (CRF)
도입
- DCNN의 translation invariance는 segmentation의 localization precision을 저하한다.
- 세가지 해결 과제가 있다.
- reduced feature resolution
- existence of objects at multiple scales
- reduced localization accuracy due to DCNN invariance
- reduced feature resolution : maxpooling, downsampling striding에 의해서 발생한다.
- filter를 upsample해서 만든, dilated convolution을 사용하여 resolution을 유지한다.
- 이 filter upsampling은 dilated convolution의 사이사이의 빈 공간(0)으로 귀결된다.
- atrous convolution, algorithme a trous 등으로 불리운다.
DeepLab v2의 계산 과정
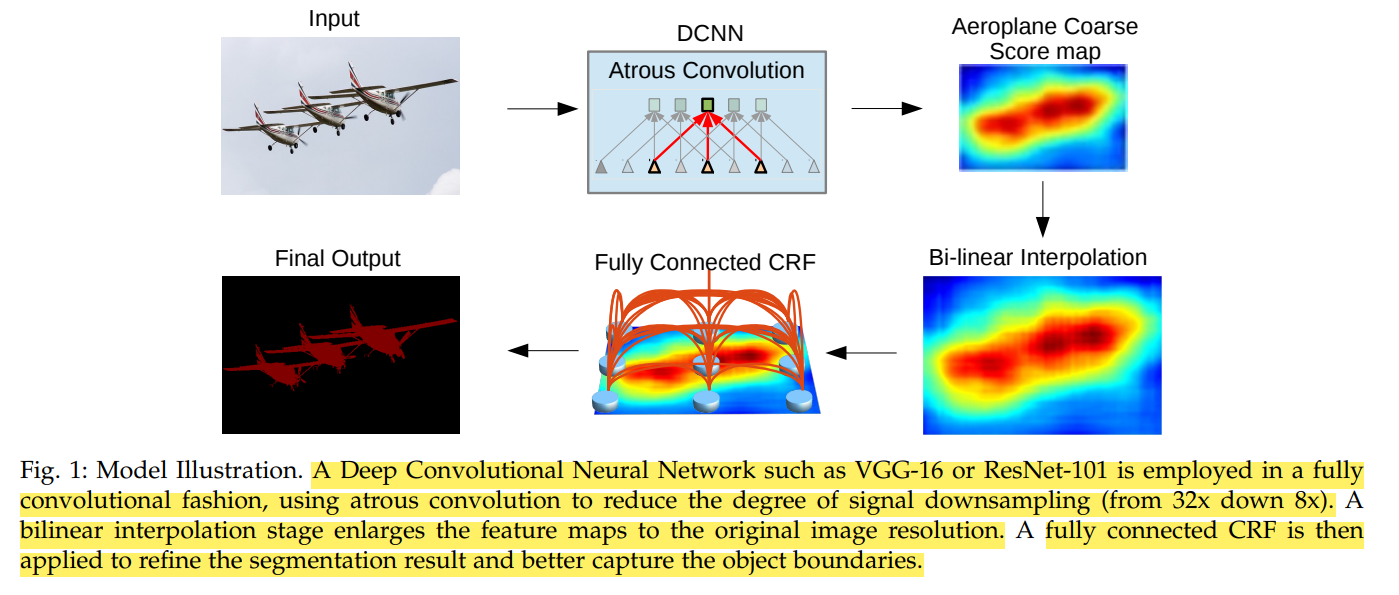
- DeepLab v1과 큰 차이가 없다는 것을 알 수 있다.
- 다만 atrous spatial pyramid pooling (ASPP)의 차이가 있다.
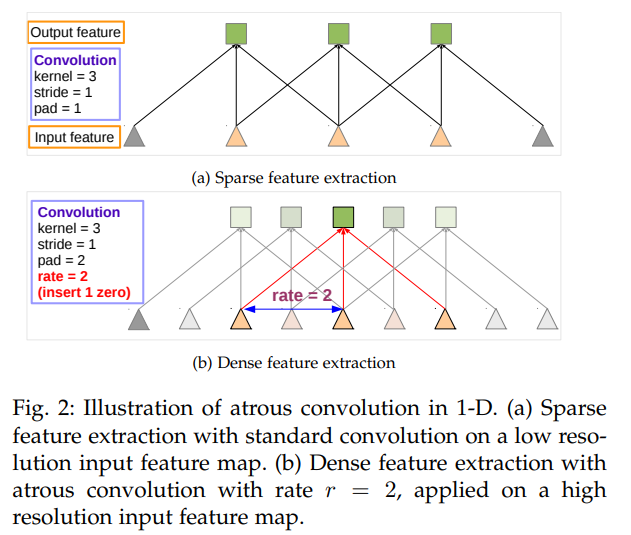
Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement
- 전 논문과 같이 dilated convolution을 수행한다.
- feature resolution을 control하기에 용이하다.
- feature 의 해상도가 점점 작아짐. 그래서 몇개의 max-pooling layer을 앲애는 대신에, up-sampling을 하는 filter를 추가.
- Segmentation 목적 상 resolution을 유지하는 데에 사용
- backbone은 원래 32 pixel upsample을 해주어야 한다. 하지만 atrous convolution을 사용하면 8 upsample로 충분하다.
- FOV(Field of View)를 크게하여 context를 크게 인식할 수 있게 한다.
- parameter의 크기가 늘어나지 않는다.
- full resolution으로 복구할 수 있다.
- upsampling은 bilinear interpolation을 이용한다.
- 이를 통해서 Bilinear Upsampling만을 사용하고, 그 결과 transposed convolution을 대체한다.
- FOV control이 쉬워지고, accurate localization (small field-of-view) & context assimilation (large field-of-view)의 trade-off를 가능하게 한다.
- Atrous Convolution을 사용하면, 모든 layer에 대해서 원하는 resolution의 feature map을 얻을 수 있다.
- score map을 구한 후에 사용할 수도, 혹은 network와 함께 training이 가능하다.
- 수식은 다음과 같다.
- $y[i]$는 output, $x[i]$는 input, $w[k]$는 filter이고, $k = length$, $r = rate$이다.
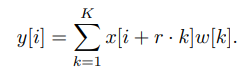
- 아래 그림은 기존의 stride를 사용한 convolution downsampling을 이용한 것과, atrous convolution을 이용한 score map의 정밀도 차이이다.
- 기존의 downsampling 이후 convolution하고, upsampling하는 방식은 각 image position에서의 score 중 1/4 정도의 pixel에서만 response를 받게 된다.
- atrous convolution을 사용해서 나온 score map이 더 정밀하다.
- filter parameter와 operation 수는 직전과 동일하다.
- feature map의 resolution을 높게 유지하도록 조절할 수 있다.

- VGG-16, ResNet-101과 같은 경우 마지막 pooling과 conv layer가 resolution을 줄이게 된다.
- atrous convolution으로 모든 conv layer를 대체하고, feature map의 density가 4배씩 상승하도록 하였다.
- 그리고 그 뒤에는 bilinear interpolation을 추가하여 다시 original image resolution으로 복귀 시키도록 하였다.
- 구현 방법은 두 가지. 후자를 사용한다.
- conv filter를 upsample한다.
- input feature map을 rate를 factor로 해서 subsample한다, rate 제곱의 resolution map을 r X r의 shift마다 deinterlacing하여 만든다.
- 이는 standard convolution을 실행하고, original image resolution에 맞도록 reinterlacing한 후에 수행된다.
Multiscale Image Representations using Atrous Spatial Pyramid Pooling
- 다양한 크기의 object를 정밀하게 segment하기 위해서 수행한다.
- 기존 방법론으로는 rescaled 된 같은 image를 DCNN에 투입시켜서 나온 feature나 score map을 결합하는 것이 있다. 하지만 연산이 많이 소요된다.
- ASPP는 multi sampling rate(convolution의 rate) 및 효과적인 FOV에서 필터를 사용하여 들어오는 convolution feature layer를 조사하여, multi scale image context & object를 획득한다.
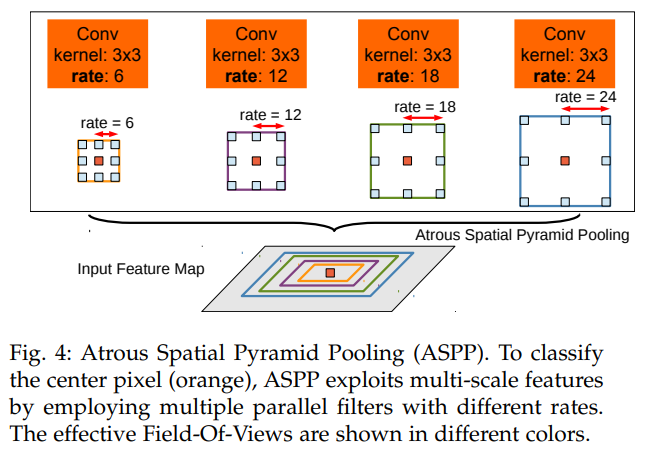
- 아래 그림과 같이, 여러 개의 rate에서 feature extraction을 한 후 1X1 conv를 가하고, 이를 Feature Piramid로 만든다.
- 이는 여러 FOV의 filter에서 original image를 sampling하는 것과 동일한 효과를 보인다.
- object와 image context를 잘 포착하게 된다.
- 특히 높은 rate로 수행하는 것이 더 성능이 좋다.
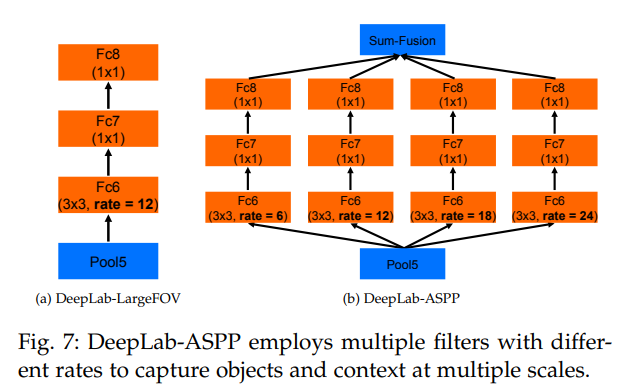
- 두가지 방법으로 구현된다. 후자를 이용.
- 같은 DCNN을 이용해서 여러 scale의 image를 넣어서 feature map을 추출한다.
- 그 후 bilinear interpolation을 이용해서 같은 크기로 rescale하고 fuse
- fuse는 각 pixel position에서 가장 큰 값(response)을 취하는 방식으로
- R-CNN spatial pyramid pooling과 같이, 하나의 single scale로 부터 추출된 feature mapdmf resampling하는 것에서 착안한다.
- sampling rate가 다른 여러 개의 atrous convolution을 병렬로 둔다.
- fuse는 위에서 언급한 대로 수행한다.
- 같은 DCNN을 이용해서 여러 scale의 image를 넣어서 feature map을 추출한다.
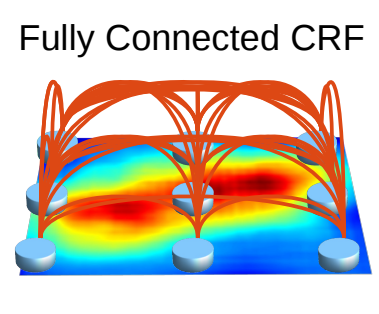
Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
- DeepLab v1처럼, CRF를 마지막에 추가해서 boundary에서의 정확도를 올렸다.
- CRF는 기존부터 Segmentation에 자주 사용되었다.
- localization 정확도를 세밀하게 높인다.
- 연산 구조. 거리가 어떻든, 모든 픽셀에 관하여 연산한다.
- 가까운 pixel이 동일한 label인 것을 선호한다.
- CRF는 기존부터 Segmentation에 자주 사용되었다.
- translation invariance를 제거하기 위한 방법으로, CRF를 기용한다.
- 이렇게 하면 spatial accuracy가 증가한다.

- 수식은 다음과 같다. 다음은 에너지 함수. $x$는 픽셀의 label
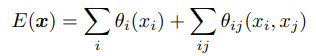
- 에너지 함수의 각 항에 대하여
- unary potential : $θ_i(x_i) = − log P(x_i)$, $P(x_i)$ 는 pxiel i의 label probability
- pairwise potential : fully connected graph, 즉 모든 node가 연결되어 있는 graph model에서 좋은 추론 결과를 보이게 하는 항이다.
- $µ(x_i, x_j ) = 1$, if $x_i \neq x_j$
- two Gaussian kernel, $w_1, w_2$
- ‘bilateral’ kernel : pixel position과 RGB color의 영향을 받는다. 비슷한 위치 비슷한 컬러를 갖는 픽셀들에 대하여 비슷한 label이 붙을 수 있도록 해준다.
- second kernel : pixel position에만 영향을 받는다. 원래 픽셀의 근접도에 따라 smooth 수준을 결정한다.
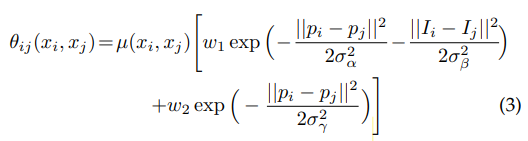
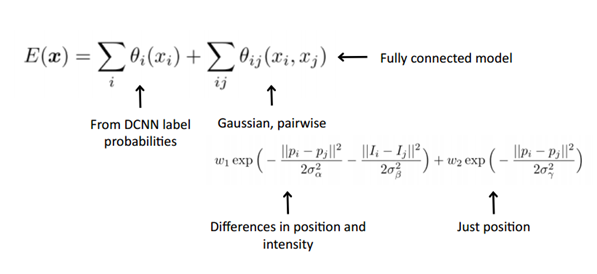
- CRF는 semantic segmentation에서 사용되는 경우, ‘multi-way classifier에 의해 계산된 클래스 점수’를 ‘픽셀간의 로컬 상호작용에 의해 저장된 low-level 정보’와 결합한다
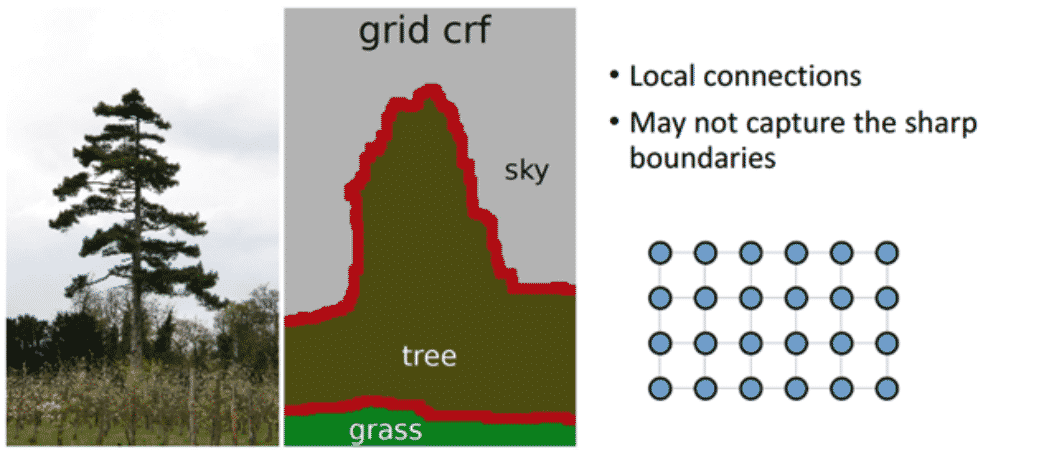
- 기존의 Short-range CRF의 경우 Local connection (Neighbor-) 정보만을 사용하게 됨
- 오히려 Segmentation이 뭉뚱그려지고, Sharp한 boundary보다는 Noise에 강인한 결과
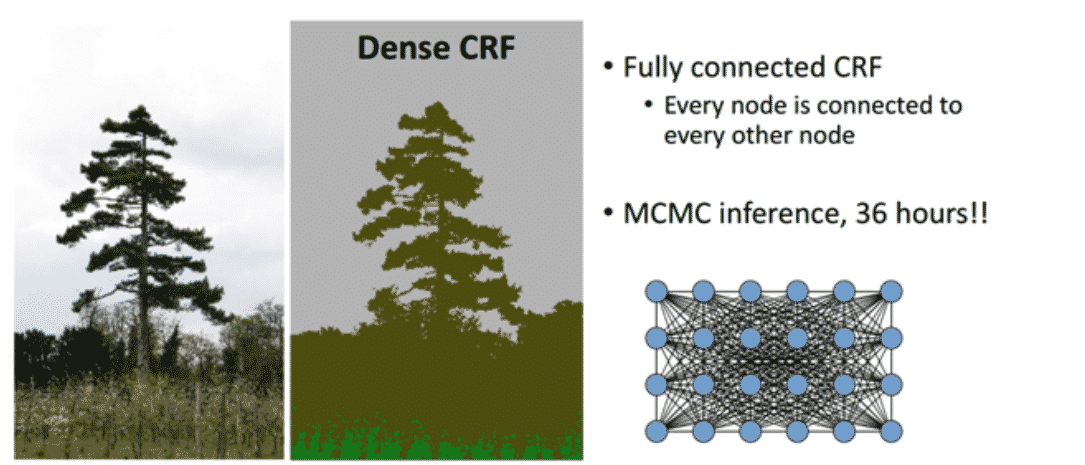
- Fully-Connected CRF / DenseCRF 이용하여 Pixel-by-pixel로 Fully Connected Graph로 연결
- 긴 연산 문제는 Mean Field Approximation이라는 방법으로 해결
- 이 방식을 적용하여 Message passing을 이용한 iteration 방식을 이용하면, 효과적(효율적)으로 DenseCRF를 수행
DeepLab v2의 효과
- Speed
- Accuracy
- Simplicity
반응형
'AI > Paper Review' 카테고리의 다른 글
| [Paper Review / Transformer]DeiT 리뷰 (0) | 2023.08.21 |
|---|---|
| [Paper Review] EPS(Explicit Pseudo-pixel Supervision) 논문 리뷰 (0) | 2023.01.08 |
| [Paper Review] DeepLab V1 논문 리뷰 (0) | 2022.08.12 |
| [Paper Review] U-Net 논문 리뷰 (0) | 2022.07.28 |
| [Paper Review] SSD : Single Shot Multibox Detector 논문 리뷰 (0) | 2022.07.06 |