SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS : DeepLab V1
- 주요 업적
- Atrous Convolution을 제안하여 Signal reduction을 최소화
- 추후 Dilated Convolution이라는 이름으로 다시 사용
- CRF 사용해서 boundary에서의 성능 향상
- Atrous Convolution을 제안하여 Signal reduction을 최소화
Introduction
- 기존 Segmentation은 Localization이 낮았다.
- fully-connected Conditioal Random Field를 이용하여 model 결과의 Fine-detail을 살린다.
- CRF의 경우 기존 Classifier의 class score와 Low-level pixel/edge information을 결합
- 계층 의존 구조(Hierarchical dependency)를 모델링하는데 Fully Connected Pairwise CRF를 사용
- 기반 모델은 VGG 16
Translation Invariance
- 아래 그림에서과 같이 고양이의 위치가 변하여도 Classification에서는 똑같이 고양이라고 분류해야한다.
- 이를 "translation invariance"라고 한다.

- 이는 다음의 3가지 과정을 통해 translation invariance하게 된다고 볼 수 있다.
- Max pooling
- CNN의 특징인 Weight sharing & Learn local features
- Softmax를 통한 확률값 계산
- 이를 아래의 알고리즘으로 개선한다.
- Hole Algorithm = Atrous Convolution = Dilated Convolution
- CRF = Conditional Random Field
- combine class scores computed by multiway classifiers with the low-level information captured by the local interactions of pixels and edges.
- 각 pixel에 대한 softmax 계산
Hole Algorithm = Atrous Convolution = Dilated Convolution
- Maxpool Layer 뒤에 따라오는 8-pixel Strided Convolution 을 사용하는 대신,
- Sparse하게 Convolution을 수행할 수 있도록 Convolution 시 중간에 Hole을 채워넣는 연산
- 같은 Kernel size의 컨볼루션을 한 번만 수행하면
- Stride의 수를 늘린것과 동일하게 Feature가 작아지는 효과
- Maxpooling을 수행하여 Global Feature를 받아내는 효과
- Receptive Field의 크기가 확장되는 효과
- Resolution이 감소하는 것을 방지하는 효과
- 연산량을 줄이는 효과

- 일반적인 CNN 방식은 위의 Sparse feature extraction 방식
- resloution(해상도)을 계속해서 줄여나가는 방법
- up-sampling을 적용시켜도 높은 resolution을 기대하기는 어렵다.
- Dense feature extraction 방식은 atrous convolution방식
- 기존 논문에서는 hole algorithm으로 불린다.
- deeplab V2이상 부터는 atrous convolution으로 불린다.

- 위의 그림은 기존의 CNN 방식에서 up-sampling을 진행한 결과
- 아래의 그림은 atrous convolution 을 사용하여 얻어낸 결과
- 더 높은 resolution

- 수식은 다음과 같다.
- 일반적인 PyTorch 구현에서는
nn.Conv2d(in_channel, out_channel, kernel_size, dilation=???)


- 의미 있는 값을 갖고 있는 것은 파란색 pixel뿐이다.
- rate parameter가 커져도 우리에게 필요한 부분은 의미를 갖는 non-zero(파란색 픽셀)부분만 보면 된다.
- 다른 부분은 다 0으로 채워져 있기 때문에, 당연히 연산량은 늘지 않고 up-sampling 효과를 불러 일으킨다.
- receptive field가 상대적으로 더 커지게 되어서, localization information이 더 많이 남게 된다.

- atrous algorithm은 FOV(Field of view)를 넓혀준다. 더불어 성능도 향상된다.
- kernel size를 줄이면 FOV가 상승하고 성능이 향상된다.
Control Receptive Field
- filter의 개수를 줄이고 filter의 spatial size를 줄여서 computation power를 줄였다.
- performance에는 영향이 없었다.
Conditional Random Fields
CRF(Conditional Random Field) · 1SoulJo

- 확률적 그래프 모델 중 하나. 특히 conditional probability를 학습한다.
- 모든 픽셀들이 그래프로 연결되어있다고 믿는 모델
- 가까운 node, 가까운 픽셀에 같은 label이 붙는 것을 선호하는 모델
- node = label of pixel
- node’s latent variable = pixel value
- node 사이를 확률 modeling
- posterior 최대화 하도록 확률 모델 학습
- Unary Term과 Pairwise Term으로 나뉜다.

- Unary Term은 FCN 등의 이미지 분류기를 사용해서 구한다.
- pairwise term의 경우, 비슷한 pixel이 label이 다르다면 energy가 증가한다.

- CRF는 계산양이 많아서 Mean Field Approximation이라는 알고리즘으로 계산한다고 한다.

- 초기화를 CNN을 거쳐서 구하고, 이를 kernel function을 거치고 weight를 거치고 transform을 거치는 등의 과정을 여러 번 반복하여 update한다.

Fully-Connected Conditional Random Field For Accurate Localization
- DeepLab V1에서는 CRF를 후처리 과정으로 사용해 예측 정확도를 높임
- 전체 픽셀에 대한 Fully-Connected CRF을 수행할 경우 높은 정확도로 Segmentation이 가능한 것으로 알려져 Fully-Connected CRF를 수행

bilinear interpolation
- bilinear interpolation을 통해 score map을 original image의 크기와 맞춤

Multiscale Prediction
- FCN과 유사하게, 중간의 feature map output을 last layer의 output과 channel 방향으로 concatenate함.
전반적인 모델 flow
- DCNN을 통해 1/8 크기의 coarse score-map을 구하고, 이것을 Bilinear interpolation을 통해 원영상 크기로 확대를 시킨다.
- Bilinear interpolation을 통해 얻어진 결과는 각 픽셀 위치에서의 label에 대한 확률이 되며 이것은 CRF의 unary term에 해당이 된다.
- 최종적으로 모든 픽셀 위치에서 pairwise term까지 고려한 CRF 후보정 작업을 해주면 최종적인 출력 결과를 얻을 수 있다.

Result


- DeepLab에 Multi scale Method를 적용하면 더 나은 성능을 보임

- Trimap(foreground, backgroud, unknown으로 분할된 이미지) Example, DeepLab 각 방법론에 대한 accuracy와 IoU

- 기존 방법과 DeepLab과의 결과물 차이

- DeepLab에 CRF를 사용했느냐 아니냐에 의 한 차이

- 기존 방법론과 DeepLab의 각 model에 따른 차이

참고자료
translation invariance
translation invariance 설명 및 정리 :: 프라이데이 (tistory.com)
아래 그림에서과 같이 고양이의 위치가 변하여도 Classification에서는 똑같이 고양이라고 분류해야한다.
이를 "translation invariance"라고 한다.
즉, CNN에서 translation invariance란 input의 위치가 달라져도 output이 동일한 값을 갖는것을 말한다
사실 CNN 네트워크 자체는 translation equivariance(variance)하다. convolution filter로 연산을 할때 특정 feature의
위치가 바뀌면 당연히 output에서 해당 feature에 대한 연산결과의 위치도 바뀌기 때문이다.
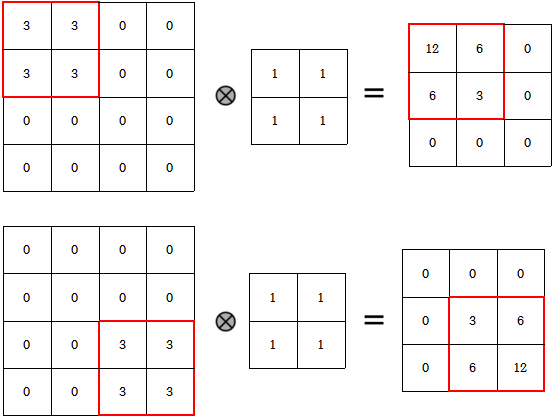
이렇듯 CNN은 translation equivariance한데 어떻게 CNN으로 이루어진 Classification이 translation invariance할까?
이는 다음의 3가지 과정을 통해 translation invariance하게 된다고 볼 수 있다.
- Max pooling
- CNN의 특징인 Weight sharing & Learn local features
- Softmax를 통한 확률값 계산
Max pooling
먼저 max-pooling은 대표적인 small translation invariance함수이다. 예시를 통해 이를 쉽게 확인할 수 있다.
orginal image의 pixel값을 [1, 0, 0, 0]이라하자.
그리고 original image를 각각 translate시킨 A, B는 [0, 0, 0, 1], [0, 1, 0, 0]의 값을 갖고 있다.
이들을 2 x 2 max pooling시키면 모두 동일하게 output으로 1을 갖는다는 것을 알 수 있다.
이처럼 Max pooling은 k x k filter 사이즈만큼의 값들을 1개의 max값을 치환시킨다.
따라서 k x k 내에서 값들의 위치가 달라져도 모두 동일한 값을 output으로 갖게된다.
"즉, k x k 범위내에서의 translation에 대해서는 invariance하다."
Weight sharing & Learn local features
CNN의 두가지 특성은 다음과 같다.
- 동일한 weight를 가진 filter를 sliding window로 연산한다. - Weight sharing
- global이 아닌 local feature들과 연산함으로써 local feature를 학습한다. - Learn local features
즉, CNN은 k x k 사이즈의 필터를 모든 픽셀에 대하여 동일 값으로 sliding window로 연산을 진행한다.
따라서 각 필터는 image내 어떤 object의 위치와 상관없이 특정 패턴을 학습하는 것이다.
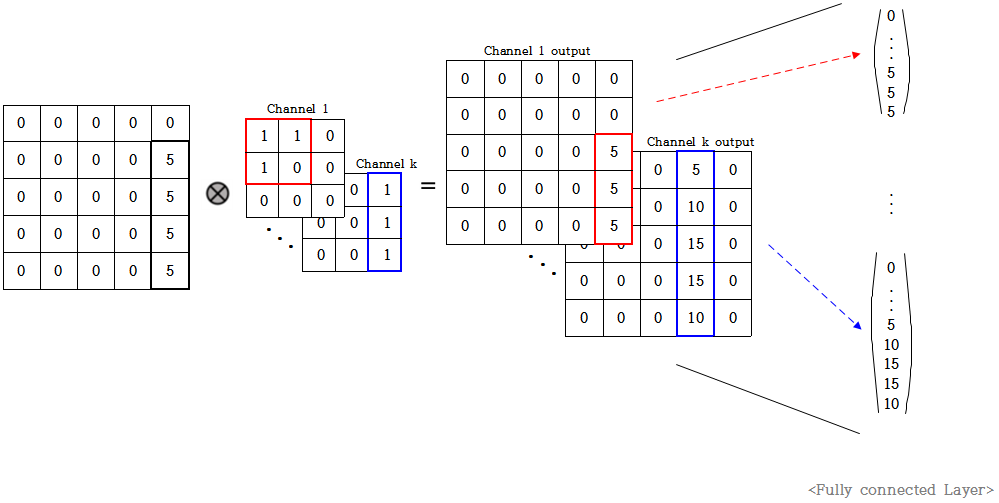
위 그림을 살펴보면 original image는 5 x 5 사이즈이고 가장 오른쪽에 길다란 어떤 object가 있음을 알 수 있다.
이 이미지에 위와같이 3 x 3 filter k개로 convolution 연산을 한다고 가정하자.
channel 1은 삼각형 모양을 한 필터이고 channel k는 original image와 같이 오른쪽에 길다란 모양을 한 필터이다.
padding을 same으로 뒀을때 convolution 연산의 결과로 위와같이 5 x 5 feature map이 k개 나온다.
이때 1번째 feature map은 삼각형 모양을 한 필터로 연산을 했으므로 그리 큰 값을 갖지 않는다.
하지만 k번째 feature map은 original image와 동일한 모양의 값을 가진 필터로 연산을 했기에 큰 값을 갖는다.
따라서 이 k개의 feature map들을 FC layer를 통해 dense하게 펼쳤을때 앞부분의 노드들은 비교적 작은 값을 갖고
마지막 뒷부분의 노드들은 큰 값을 갖는다. 그러나 여기까지도 아직은 translation equivariance하다.
FC layer의 특성상 FC 이전의 모든 network가 invariant하면 first FC도 invariant할 수 있지만
위에서 설명했듯이 CNN은 equivariance이므로 현재 전체 network도 아직은 equivariance이다.
그러나 위 그림을 보면 알 수 있듯이 각각의 노드 값의 위치가 object의 위치에 따라 달라질 수 있어서
아직은 equivariance하지만 위치가 달라져도 5 x 5 사이즈 내에서만 달라진다는것을 알 수 있다.
따라서 동일 가중치를 모든 픽셀이 공유하면서 local하게 연산하기에 FC layer에서의 output값들도
input image의 local value들의 영향을 받아 특정 사이즈 내에서만 equivariant하게 값이 바뀐다.
Softmax를 통한 확률값 계산
위 과정까지는 아직 translation equivariance하다. 그러나 이를 invariance하게 만들어주는 과정이 Softmax과정이다.
Classification에서는 feature map들을 FC layer와 연결하고 마지막 label개수만큼 output node를 설정하여
최종적으로 이들을 softmax를 통해 classification 결과를 결정한다. 위 예에서 output label은 10개라고 가정하자.
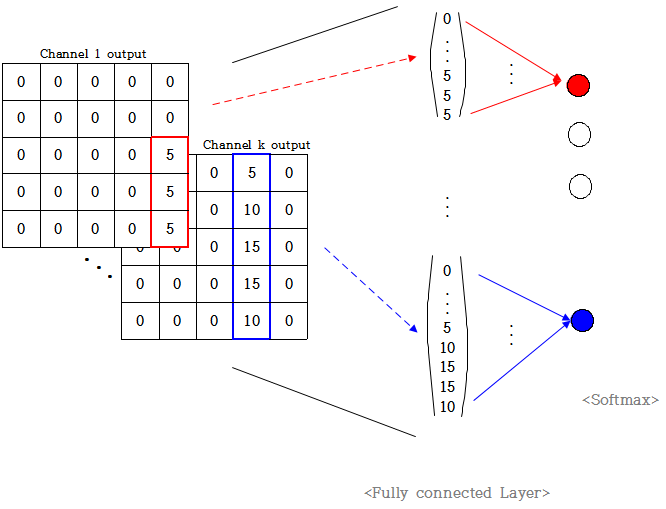
위 그림을 보면 마지막에 output label k개와 FC layer를 연결하였고 마지막에 softmax로 output값을 결정한다.
이때 각 output node가 channel개수만큼의 노드들과만 대응되도록
weight를 channel개수만큼만 1로하고 나머지는 0으로한다고 가정해보자.
즉, 위 예시에서 output node 1은 1~25 노드와 weight 1로 연결되어있고 나머지는 weight 0으로 연결됐다.
마찬가지로 output node k는 마지막 25개 노드와 weight 1로 연결되고 나머지는 weight 0으로 연결됐다.
따라서 위 예시와 같이 feature map k에 높은 값들이 많이 있으면 output node k는 높은 값을 갖는다.
최종적으로 이들을 softmax로 연산하면 결국 output으로 node k가 나오게 된다.
결국 classification으로 output k가 나오기 위해서는 feature map k에 높은 값이 많으면 되는 것이고
feature map k에 높은 값이 많으려면 channel k와 original image가 비슷한 패턴을 갖고 있어야 한다.
"즉, object의 위치와 상관없이 패턴이 동일하면 동일한 output을 갖게 된다"
Reference
https://www.youtube.com/watch?v=JiC78rUF4iI&t=6s&ab_channel=TaeohKim
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials (illinois.edu)
GitHub - RobolinkInc/Zumi_Content: zumi lesson and demo
이후에는 DeepLab V2와 CRF 논문을 읽어봐야할 것 같다. 이왕 시작한 거 Segmentation 위주로 논문을 봐야지…
'AI > Paper Review' 카테고리의 다른 글
| [Paper Review] EPS(Explicit Pseudo-pixel Supervision) 논문 리뷰 (0) | 2023.01.08 |
|---|---|
| [Paper Review] DeepLab V2 논문 리뷰 (0) | 2022.08.24 |
| [Paper Review] U-Net 논문 리뷰 (0) | 2022.07.28 |
| [Paper Review] SSD : Single Shot Multibox Detector 논문 리뷰 (0) | 2022.07.06 |
| [Paper Review] GG-CNN : Closing the Loop for Robotic Grasping 리뷰 (0) | 2022.06.26 |