Paper Link
https://arxiv.org/abs/1512.02325
Abstract
single deep neural network를 이용해서 object를 detecting하는 방법에 관한 논문이다.
SSD는 bounding box의 output space를 default box의 집합으로 이산화한다. 이 때 그 bounding box의 aspect ratio와 scale을 feature map을 기준으로 여러 개로 만든다.
prediction time에는, network가 object category에 관한 score와 object shape에 더 알맞은 bounding box adjustment를 출력한다. 또한, network는 object를 여러 개의 size로 다루기 위해서, 여러 개의 feature map으로부터 prediction을 combine한다.
SSD는 기존 model에 비해서 구현하기 간단하다. Region Proposal, pixel/feature resampling stage가 없으며, 모든 연산을 하나의 network에 통합하였기 때문이다. 이러한 점 때문에 Real-time 환경에서 적용하기 적합하다.
Introduction
기존 SotA Object Detection model은 bounding box를 가정하고, bounding box 내의 pixel/feature를 resample하고, classifier를 적용하는 순서를 따랐었다. 이러한 모델의 경향은 Selective Search를 채택한 R-CNN부터 본 논문 발표 시점에서의 Faster R-CNN까지 이어졌다.
하지만 이런 기존 방법은 computationally expensive했다. 대표적으로 가장 성능 좋고 빠르다고 평가받는 FAster R-CNN도 출력하는 초당 프레임의 수가 7FPS라고 한다. 이를 개선하기 위해서 각 detection pipline의 stage를 attack 하는 시도 등이 있었지만, 효과적으로 연산속도를 올린 것은 결국 detection accuracy를 낮추는 일 밖에 없었다.
본 논문에서는 pixel / feature resampling을 하지 않고, bounding box hypotheses를 하지 않으면서 어느 정도 accuracy가 보장되는 방법을 최초로 선보인다. 성능 개선 정도는 논문을 이 리뷰에 직접 적지는 않겠다. 단지 속도면에서 성능이 대폭 상향되었다는 것만 기억하면 된다. 이는 bounding box proposal과 pixel / feature resampling stage를 없앤 덕분이라고 한다.
또한, 본 논문에서 발전한 부분에는 다음과 같은 것이 있다.
- small convolution filter를 각 feature map에 적용함으로써, 고정된 default bounding box의 집합에 대해, object의 category와 bounding box location의 offset를 prediction한 것
- high detection accuracy를 위해서, aspect ratio마다 서로 다른 predictor(filter)를 사용하여 완전 개별적인 prediction을 하고, 이 filter를 마지막 stage에서 여러 개의 scale의 feature maps에 적용하여, 서로 다른 multiple scale의 prediction(detection)을 만든다.
- 이런 수정을 통해서, 특히나 각기 다른 scale에서의 prediction에 multiple layer를 사용함으로써, 낮은 해상도의 input을 통해서도 높은 accuracy를 얻을 수 있고, detection speed도 향상시킬 수 있다.
The Single Shot Detector (SSD) Models
SSD framework에 대한 소개와, training methodology와 model의 dataset에 따른 특성과 실험결과를 설명하였다.
Model
SSD는 데이터로 input image와 ground truth bounding box가 필요하다. 아래 그림과 같이, input image에 convolution을 가해서 구한 다양한 크기의 feature map에서, 각 pixel마다 default box를 지정한다. 여기서 이 default box는 여러 개의 aspect ratio로 되어있다.
여기서 각 default box에 대해서 예측해야하는 것은 shape offset과 object category에 관한 confidence이다.
training time에는, 다음과 같은 순서를 따른다.
- default box를 ground truth box에 맞춘다.
- 아래의 그림을 예로 들자. 고양이의 경우 $8 \times 8$의 feature map에서 두 개의 default box에 대해서 match가 되어 positive로 처리되었고, 개의 경우 $4 \times 4$의 feature map에서 한 개의 default box에 대해서 match가 되어 positive로 처리되었다.
- 나머지 default box는 모두 negative로 처리된다.
- loss는 Smooth L1으로 게산된 localization loss와, Softmax로 계산된 confidence for object category loss의 가중합으로 구한다.

방금 말했듯이, SSD는 convolution을 통해서 fixed size의 bounding box를 여러 개 만들고, 각 object의 class에 대한 score를 예측한다. 이 과정에서 non-maximum suppression step을 거쳐서 final detection을 한다.
여기서 convolution을 통해서 여러 개의 feature map을 생성하기 전에 존재하는 network layer는, 다른 image classification model에서 마지막 classification layer부분을 잘라서 base network로써 사용할 것이다. 그리고 여기에 추가로 convolution을 통해서 여러 개의 feature map을 생성하는 layer를 붙일 것이다.
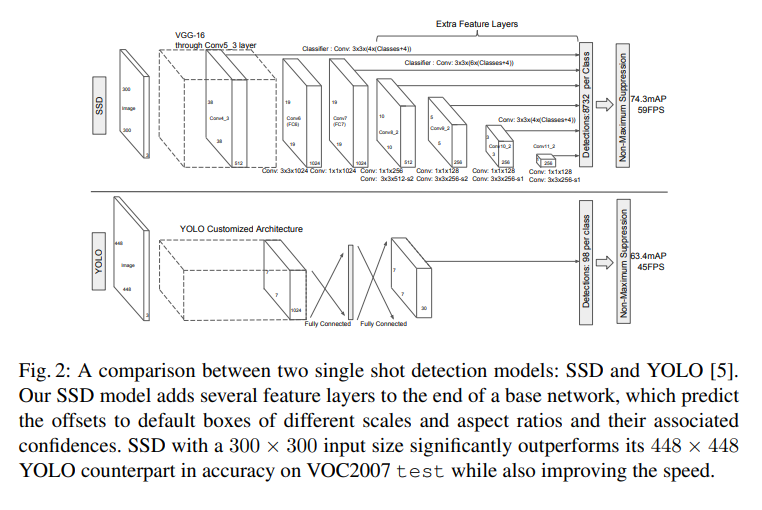
SSD의 Model Architecture. 아래는 Yolo의 Architecture
- Multi-scale feature maps for detection
- 마지막 convolutional layer를 통해서 얻은 여러 개의 feature map을 통해서 multiple scale prediction이 가능하게 된다.
- 아래 그림에서 볼 수 있듯이,그 convolutional layer 뒤에 classification prediction을 위해서 covolution model에 더 추가로 붙는데, 이들은 각 feature layer마다 다르다.
- Convolutional predictors for detection
- 앞서 말한 classification prediction을 위한 convolutional model을 설명하는 것이다.
- 각 convolutional feature layer에서부터 fixed set of detection prediction을 convolutional filter를 이용하여 만든다.
- 만약 feature layer의 size가 $m \times n$, $p$ channel이었다면, $3 \times 3 \times p $의 convolution filter를 이용해서 score for category, shape offset realtive to default box를 계산한다. 커널이 적용되는 곳 마다 output value가 생성되며, 각 feature map loation에서 bounding box offset output value 또한 default box position에 대해 상대적으로 생성된다.
- Default boxes and aspect ratios
- Convolution Layer를 통해서 추출한 feature map의 각 cell(pixel)에 모두 set of default bounding box를 지정한다. 이를 통해서 multiple feature map을 추출한다.
- 해당 cell에 대응되는 default box의 위치가 고정되도록, default box는 feature map에 convolution 방식으로 타일링한다.
- 각 feature map cell에서, 그 cell의 default box에 대한 offset과 해당 box 내에서의 class score를 예측한다.
- 그렇게 각 default box $k$개 마다, $c$개의 calss score를 계산하고 4개의 offest을 구하게 된다.
- 그 결과 feature map에서 각 location마다 $(c+4)k$의 filter가 가해진다는 뜻이며, 그 결과 $(c+4)kmn$의 output을 내보내게 된다.
- 여기서 default box는 Faster R-CNN에서의 anchor box와 유사하지만, default box는 여러 개의 resolution인 여러 개의 feature map에 배치한다는 차이가 있다. 이는 output으로 나오는 bounding box의 크기를 효율적으로 구분짓게 한다.
Training & Result
Region Proposal을 사용하는 detector와 SSD의 가장 큰 차이는, SSD는 detector output에 ground truth information을 할당해야한다는 점이다. 이 정보가 주어지고나면, loss function과 back propaation은 처음부터 끝까지 한번에 계산된다.
Training 과정에는 default box와 detection scale을 고르는 것, 그리고 hard negative mining과 data augmentation 전략에 대해서 기술한다.
- Matching Strategy
- 각 ground truth box마다, default box를 선택해야하는 문제이다. 이 default box는 여러 개의 location, aspect ratio, scale이 있다.
- jaccard overlap(IoU)을 통하여, GT box와 default box를 matching한다.
- default box를 GT box 중 threshold 0.5를 넘는 것에 아무것이나 matching한다. 이를 통해서 model이 여러 개의 overlapping default box에 대해서 높은 score를 predict하게 한다.
- Training objective
- objective function은 Multibox objective를 사용한다. 다만 조금 수정해서 여러 개의 category에 맞도록 수정했다.
- 전체 objective loss function은 localization loss(loc)와 confidence loss(conf)의 가중합이다.
- $x^p_{ij} = {1, 0}$는 $i$번째 default box를 $j$번째 ground truth box에 맞는 지 아닌지 확인하는 indicator라고 하자. 여기서 해당 GT box의 category는 $p$인 경우이다.
- matching strategy에 따르면, 모든 default box에 대해서 합산하면 $\Sigma x^p_{ij} ≥ 1.$일 수 있다.
- 수식은 다음과 같다. 여기서 $N$은 default box의 개수이다. 만약 $N=0$이라면 loss는 0으로 취급한다.
- 참고로 weight factor $\alpha$는 cross validation 결과 1로 지정하였다고 한다.
- objective function은 Multibox objective를 사용한다. 다만 조금 수정해서 여러 개의 category에 맞도록 수정했다.

- Localization loss는 Smooth L1 loss이다. predicted box $l$과 GT box $g$ 사이의 L1 loss라고 생각하면 된다.
- default bounding box$(d)$의 offset of center $(cx, cy)$와 width $(w)$, height $(h)$에 대해서 regression을 수행한다.
- 수식은 다음과 같다.

- confidence loss는 softmax loss이다. 전체 class confidence $(c)$를 계산한다.

- Choosing scales and aspect ratios for default boxes
- 하나의 network에서 여러 개의 convolution layer를 통해 얻은 feature map을 이용함으로써, 이미지를 다양한 scale로 만들어서 combine한 것과 동일한 효과를 볼 수 있다.
- 이전 연구에서 영감을 받아서, lower feature map과 high feature map을 동시에 사용한다.
- 이전 연구에서, 입력층에 가까운 lower layer를 사용하면 fine detail을 더 잘 포착하기에 semantic segmentation quality를 높일 수 있다는 연구가 있었다.
- 또한, feature map을 통해 얻은 전반적인 context를 추가하여 segmentation 결과를 조금 더 개선할 수 있다는 연구도 있었다.
- 그런데, 이전 연구에 따르면, 각기 다른 level에서의 feature map은 서로 다른 receptive field size를 가지게 된다. 하지만 SSD에서는 default box가 각 layer의 실제 receptive field에 반드시 대응될 필요가 없다.
- 이는 특정한 feature map이 특정한 object scale에 반응하게 학습하도록 default box의 tiling을 설계하여 해결한다.
- $m$개의 feature map을 prediction에 사용한다고 하자. 그러면 각 feature map에서 계산하는 default box의 scale은 다음과 같다.

- 예를 들면 $s_{min}$이 0.2이고, $s_{max}$이 0.9라면, lowest layer에 scale이 0.2이고, highest layer에 0.9라는 것이다. 그리고 그 사이에 있는 layer에 대해서는 모두 균등한 간격으로 scale이 지정된다.
- 각 default box에 각기 다른 aspect ratio를 할당한다. 이는 다음과 같이 한다.

- 여기서, width와 height는 각 default box에 대해서 다음과 같이 계산한다.

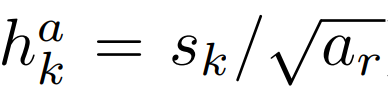
- 만약 aspect ratio가 1이라면, 다음 과 같은 scale의 default box를 하나 추가해서, 총 6개의 default box를 각 feature map location마다 지정해준다.
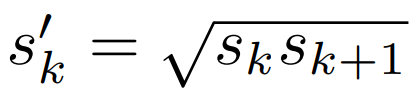
- center of default box는 다음과 같이 지정한다. 여기서 $|f_k|$는 k번째 square feature map의 size이다. 단, $i,j \in [0,|f_k|]$

distribution of default box를 특정한 dataset에 맞도록 설계할 수도 있지만 이는 open question이다.
- 결과적으로, 많은 feature map 위의 모든 location에 대해서 여러 개의 scale과 aspect ratio로 default box를 생성해서 prediction을 하고, 이를 combine하게 되는 것이다. 이를 통해서 여러 개의 input size와 shape을 커버하게 된다.
- 위의 개 사진을 다시 보도록 하자.
- 개는 $4 \times 4$ feature map에서는 matching이 되지만, $8 \times 8$ feature map에서는 matching이 되지 않는 것을 볼 수 있다.
- 이는 개에 match가 되지 않는 scale을 가진 box가 있기 때문이며, 이들은 training 동안에는 negative로 취급된다.

- Hard negative mining
- 모든 object detection 문제에서 발생하는 일이지만, matching step 이후, default box 중 negative인 것이 압도적으로 많다. 이는 특히 possible default box가 클 때 더욱 심하다.
- 이는 positive와 negative training example의 불균형을 일으킨다. 그래서, negative sample들을 confidence loss로 각 default box에 대해서 내림차순 정렬을 한 후, 그 중에서 가장 높은 것을 골라서, negative와 positive가 3:1의 비율을 유지하도록 만들었다.
- 그 결과 더 빠른 optimization과 더 안정적인 학습이 가능해졌다.
- 아래에 Hard negative mining에 대한 자세한 설명을 적어놓았다.
- Data Augmentation
- 다양한 input size와 shape에 robust하게 만들기 위해서 다음 옵션에 따라서 training image가 랜덤하게 추출되었다.
- 전체 원본 이미지
- object와의 최소 IoU가 0.1, 0.3, 0.5, 0.7, 0.9가 되도록 patch를 추출한다.
- 랜덤하게 patch를 추출한다.
- 그 결과, patch의 size는 원본 이미지에 비교해서 0.1에서 1까지 존재한다. 그리고 aspect ratio는 1/2와 2이다.
- 만약 GT box의 중심점이 sample된 patch 내에 존재한다면, GT box와 겹친 부분은 남겨둔다.
- 이후, sample된 patch는 고정적인 size로 조절되고, 0.5의 확률로 수평으로 뒤집는다. 그리고 다음 논문과 유사한 방식으로 photo-metric distortion을 가한다.
- Howard, A.G.: Some improvements on deep convolutional neural network based image classification. arXiv preprint arXiv:1312.5402 (2013)
- 다양한 input size와 shape에 robust하게 만들기 위해서 다음 옵션에 따라서 training image가 랜덤하게 추출되었다.
Experiment
- Base Network
- ILSVRC CLS-LOC dataset에서 pretrained된 VGG16을 기반으로 실험을 진행
- 6, 7번째의 fully connected layer을 paremeter만 subsample하고, convolution layer로 대체하였다.
- 또한, 5번째 max poolin layer도 $2 \times 2$를 $3 \times 3$로 변경하였다.
- Semantic image segmentation with deep convolutional nets and fully connected crfs. In: ICLR. (2015)
- hole을 채우기 위해서 'a trous algorithm'을 사용하였다.
- A real-time algorithm for signal analysis with the help of the wavelet transform. In: Wavelets. Springer (1990)
- dropout layer와 8번째 fully connected layer는 삭제했다.
- 그 결과 발생한 모델을 SGD, learning rate $10^-3$, 0.9 momentum, 0.0005 weight decay, batch size 32로 fine tuning 한다.
- learning rate decay policy는 dataset마다 다르게 했다.
- PASCAL VOC2007
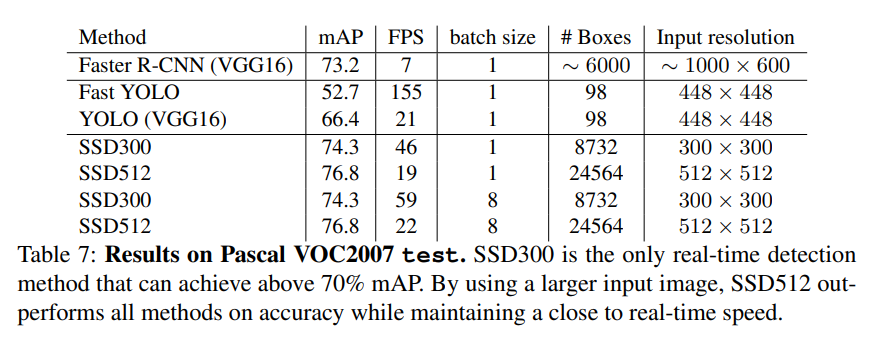
- Fast R-CNN과 Faster R-CNN에 비교한다. 모든 method는 pre-trained VGG16 network를 기반으로 fine tune 되었다.
- 아래는 SSD의 모델 구조도이다.
- conv4_3, conv7 (fc7), conv8_2, conv9_2, conv10_2, and conv11_2를 location과 confidence를 예측하기 위해서 사용한다.
- default box는 conv4_3에서 scale 0.1로 잡았다.
- 새로 추가된 convolution layer는 xavier method로 초기화 했다.
- conv4_3, conv10_2, conv11_2의 경우, 4개의 default box만 사용한다. 즉, 1/3와 3의 aspect ratios는 제외한다.
- 다른 layer에서는 모두 6개의 default box를 사용하였다.
- conv4_3는 다른 layer와 비교해서 특수한 feature scale이 있으므로, L2 normalization을 이용해서 feature map의 각 위치에 있는 feature norm을 20으로 scale하려고 했고, back propagation 동안 그 scale을 학습하려고 했다.
- ParseNet: Looking wider to see better. In: ILCR. (2016)
- $10^-3$ learning rate, 40k iterations, 그 후엔 10k iterations with $10^-4$ and $10^−5$으로 학습시켰다.

- VOC2007 trainval에 학습하면, SSD300($300 \times 300$인 image에 학습시킨다는 의미)으로도 Fast R-CNN의 성능을 넘어선다.
- SSD512의 경우 Faster R-CNN의 성능을 넘어선다.
- 그 외에 COCO trainval35k 등에서 학습시켜도 좋은 성능이 나온다.
- 자세한 결과는 아래 표와 같다.

Model Analysis
- SSD 모델은 다양한 크기, 다양한 object를 높은 quality로 detect할 수 있다. 이는 다음 그림에서 볼 수 있다.
- Recall은 85 ~ 90% 이고, 0.1 IoU인 경우(weak criteria)에서 더욱 높아진다.
- R-CNN과 비교하면, localization error가 적다. 그 이유는 object shape을 바로 regress 하도록 학습하고, 또한 여러 개로 분리되지 않고 단 하나의 step을 통해서 object의 category를 classifying하기 때문이다.
- 하지만, 비슷한 카테고리의 object에 대해서는 혼동하는 모습을 보였다.
- 이는 하나의 location에 대해서 여러 개의 category를 예측하려고 해서 그렇다.
- 또한, SSD는 bounding box의 size에 민감했다.
- 작은 bounding box를 지닌, 작은 object에 대해서는 좋지 못한 성능을 보였다.
- 이는 작은 object가 최상단 layer에서는 information이 적을 수 밖에 없기 때문이다.
- 연속적인 convolution에 의한 것.
- 따라서 input size를 늘리는 것은 작은 object를 인식하는데 도움이 된다.
- 다양한 object aspect ration에 robust했다.
- feature map의 각 위치마다 다양한 aspect ratio의 default box를 사용했기 때문이다.
- 하지만, 비슷한 카테고리의 object에 대해서는 혼동하는 모습을 보였다.

위 그림은 각각 다음의 수치를 보여준다.
- Cor : correct
- Loc : false positive due to poor localization
- Sim : confusion with similar categories
- Oth : confusion with others
- BG : confusion with background
- 붉은 실선 : strong criteria(0.5 IoU)에서 detection의 개수가 늘어남에 따라서 변화하는 recall을 표현한다.
- 붉은 점선 : weak criteria(0.1 IoU)에서 detection의 개수가 늘어남에 따라서 변화하는 recall을 표현한다.
bottom row의 graph는 top-ranked false positive type의 분포를 표현한다.
이제는 실험 결과를 보며, 모델의 각 component가 performance에 어떤 영향을 끼쳤는지 확인하자.

Data Augmentation
- 앞서 언급한 data augmentation 방법(Yolo에서의 방법과 비슷하다.)을 통해서 mAP가 8.8% 상승했다.
- SSD와 비교해서, Fast / Faster R-CNN은 이런 data augmentation으로 이득을 보기 어렵다.
- Fast / Faster R-CNN은 feature pooling stage가 있어서, 사실상 모델 내에서 data augmentation이 곧바로 되기 때문이다.
More default box shapes
- aspect ratio 1/3과 3을 없애서 실험해본 결과 0.6% 만큼 정확도가 하락했다.
- 1/2와 2를 없애면 2.1% 만큼 정확도가 낮아졌다.
- 여러 개의 aspect ratio의 default box를 사용하면 정확도가 상승한다.
Atrous is faster
- Atrous라는 말은 난해하다는 의미이다.
- 여기서 atrous version of a subsampled VGG16라는 말은, pretrained VGG를 가지고 와서 모델 형태를 앞서 언급한 것처럼 변화시켰다는 의미이다.
- VGG16 모델을 그대로 가지고 와서 convolution layer만 추가하면, 성능은 동일하지만 속도가 20% 정도 느려진다고 한다.
Multiple output Layers at different resolutions
- SSD의 성능의 근간은 ‘각기 다른 output layer에 각기 다른 scale을 가진 default box를 사용’하는 것이다. 이 부분의 advantage를 확인하기 위해서 layer를 제거하고 결과를 비교했다.
- 적절한 비교를 위해서 layer를 없앨 때마다 default box tiling의 수(8732)를 비슷하게 유지하기 위해서 adjust 과정을 거쳤다.
- 보통은 남은 layer의 각각의 box에 scale을 추가하는 방식으로 수행되었다. 이 과정에서 scale도 조정되었다.
- 아래 Table을 통해서 layer가 줄어들 수록 정확도가 낮아지는 것을 볼 수 있다.
- 하나의 layer에 여러 개의 scale을 도입하면, 대부분은 image boundary에 있으므로 주의하여 처리해야 한다.
- 여기서 Faster R-CNN에서 했던 것처럼 boundary에 존재하는 box는 무시했다.
- Coarse Feature map(최상단 layer, 출력층 근접)(conv11_2 (1 × 1) or conv10_2 (3 × 3))을 사용한 경우, performance가 크게 낮아졌다.
- 이는 pruning 이후에는 큰 물체를 커버할 만큼 충분히 큰 bounding box를 만들기 어렵기 때문이다.
- 그래서 finer resolution feature map(최하단 layer, 입력층 근접)를 사용하면 성능이 다시 상승한다. 이는 pruning 이후에도 큰 물체를 커버할만한 bounding box가 남아있기 때문이다.
- SSD의 prediction은 ROI pooling에 의존하지 않으므로, low-resolution feature map(최상단 layer, 출력층 근접)에서 collapsing bins 문제에서 자유롭다.
- SSD는 다양한 resolution의 feature map에서 수행한 prediction을 결합하여 R-CNN 계열보다 더 좋은 성능을 보이며, low resolution input image를 사용할 수 있다.

아래의 그래프를 보자.
좌측 그래프는 Bounding box의 효과를 보여준다. 우측 그래프는 Aspect Ratio의 효과를 보여준다.
아래는 위 그래프에서의 표기의 의미이다.
- Bounding Box Area: XS=extra-small; S=small; M=medium; L=large; XL =extra-large.
- Aspect Ratio: XT=extra-tall/narrow; T=tall; M=medium; W=wide; XW =extra-wide.

PASCAL VOC2012
- learning rate : $10^-3$, 60k iteration → $10^-4$, 20k iteration
- 아래 table은 SSD300과 SSD512의 결과이다.
- YOLO와 비교했을 때, SSD는 feature map의 각 위치에서 convolutional default box를 여러 사이즈로 사용한 효과로 더 좋은 성능을 보였다.

COCO
- PASCAL dataset 보다 크기가 작아서, default box의 크기도 줄였다.
- scale of 0.15 instead of 0.2, and the scale of the default box on conv4_3 is 0.07 (e.g. 21 pixels for a 300 × 300 image)
- learning rate : $10^−3$, 160k iterations → $10^-4$, 40k iterations → $10^-5$, 40k iteration
- 이 실험을 통해서도 큰 물체에 대해서는 크게 mAP가 상승했지만, 작은 물체에 대해서는 mAP가 조금만 상승함으로써, 작은 물체에 대한 인식이 어렵다는 것을 보여줬다.
- 추측이지만 Faster R-CNN이 2 stage여서 작은 물체에 대해서는 더 좋은 성능을 보일 것이라고 한다.
아래 사진은 COCO test-dev를 통해서 detection example을 구한 것이다.

아래는 COCO dataset에서 실험한 결과이다.

Data Augmentation for Small Object Accuracy
- 아래 Fig. 4에서 나와있듯이 feature resampling step이 없는 SSD에서는 작은 물체를 인식하는 것이 어렵다.
- 그래서 작은 물체를 위해서 특별히 Data Augmentation을 수행한다.
- 앞서 언급한 Zoom out 연산이 바로 작은 물체를 더 잘 인식시키기 위해서 존재한다.
- image를 random하게 ($16 \times$ original image size, filled with mean value)의 canvas에 놓고, random crop한다.
- 이렇게 training image가 2배가 되면, training iteration도 2배가 되어야한다.
- 아래 그래프를 통해서 Data Augmentation for Small Object가 큰 효과를 보임을 알 수 있다.
- 아래 row가 SSD300, SSD512 모델을 data augmentation을 수행하여 학습 시킨 결과이다.
- 작은 물체에 대한 인식율이 나아진 것을 볼 수 있다.

- 아래 Table 또한 같은 결과를 보인다.

Inference Time
- SSD 특성상 defauly box의 개수가 매우 많으므로, NMS(non-maximum suppression)을 하지 않으면 inference를 제대로 할 수가 없다.
- confidence의 threshold를 0.01로 정하면 대부분의 box를 제거할 수 있다.
- 그리고 NMS를 가한다. IoU는 각 카테고리마다 0.45 이상으로 정하고,
- 이미지 당 200개의 detection을 유지하도록 설정한다.
- 아래 Table은 SSD와 Faster R-CNN과 YOLO와 비교한 것이다.
- forward time 중 80%는 base network인 VGGnet에서 사용했다.
- 즉, 더 빠른 base network로 변경하면 속도가 더 빨라질 것이고, real time에 더욱 적합해진다.
Conclusion
- top of the network에서, 다양한 크기의 feature map에 다양한 크기의 convolution bounding box output을 사용해서 prediction을 수행한다.
- 기존 모델만큼 정확하고 빠르다.
- 기존 방법보다 box predictions sampling location, scale, aspect ratio가 최소 한 단계 더 큰 SSD 모델을 구축할 수 있다.
- 59FPS의 real time 성능을 보인다.
모르겠어서 찾아 본 것
Collapsing Bins Problem
ROI를 사용하여 detection을 사용하는 모델(R-CNN 계열)에서 발생하는 문제.
non-maximum suppression (NMS)
https://github.com/engineerJPark/EECS-498/blob/master/Lecture 15/Lecture 15 Object Detection.md#overlapping-boxes--non-max-suppressionnms
비최대 억제라고도 한다.여러 개의 bounding box가 서로 겹쳐 있는 상태에서 하나의 bounding box만 남겨놓기 위해서 사용하는 기법이다.
가장 높은 확률을 가진 bounding box를 구한 후, 다른 bounding box와 IoU를 비교해서 threshold를 넘기면 제거한다. 즉, duplicate로 본다는 의미이다. 보통 이 threshold는 0.7로 정한다.

0.78인 주황색 bounding box를 제거한다.

0.74인 노란색 bounding box를 제거한다.

이렇게 가장 높은 score의 bounding box만 남는다.
Hard Negative Mining
hard negative = 실제로는 negative, 하지만 positive로 잘못 예측하기 쉬운 데이터이다. 즉, 모델을 통과했을 때, 해당 샘플에 대해서 negative라고 해야하는 데, confidence score가 높게 나오는 것이다.
아래의 그림을 보자

모델에서 예측을 사람으로 하면 Positive, 배경으로 하면 Negative라고 한다고 하자. 그리고 모델이 맞는 예측을 하면 True라고 하고, 틀린 예측을 하면 False라고 하는 것이다.
여기서 hard negative mining은 hard negative data를 모으는 것이다. 그렇게 얻은 데이터를 원래의 dataset에 추가해서 다시 학습 시키면 False Positive error에 robust해진다.

참고로 Object Detection 문제에서 False Postive/Negative가 발생하는 이유는, 모델에서 이미지를 거쳤을 때, positive에 비해서 negative patch가 매우 많은데, 정작 training data로 주어지는 bounding box는 모두 사람을 둘러싼 것이기 때문이다. 즉, 클래스 불균형 문제가 발생한다. 수많은 patch 중 아주 약간의 Positive patch가 있는데, True Negative Patch가 무엇인 지 알지도 못하는 상황에서 이것을 학습해야하는 일은 어렵다.
그래서 hard negative mining을 통해서 배경을 negative로 확실하게 지정해주어서, 배경 patch와 사람 patch가 비율이 맞도록 해주고, 모델이 정확하게 학습하도록 하는 것이다.
Hyperparameter Tuning by Cross validation
다음 링크를 참고하라.
https://cinema4dr12.tistory.com/1275
https://tensorflow.blog/머신-러닝의-모델-평가와-모델-선택-알고리즘-선택-3/
Layer에 대한 명칭
Reference
https://cocopambag.tistory.com/15
https://herbwood.tistory.com/15
'AI > Paper Review' 카테고리의 다른 글
| [Paper Review] EPS(Explicit Pseudo-pixel Supervision) 논문 리뷰 (0) | 2023.01.08 |
|---|---|
| [Paper Review] DeepLab V2 논문 리뷰 (0) | 2022.08.24 |
| [Paper Review] DeepLab V1 논문 리뷰 (0) | 2022.08.12 |
| [Paper Review] U-Net 논문 리뷰 (0) | 2022.07.28 |
| [Paper Review] GG-CNN : Closing the Loop for Robotic Grasping 리뷰 (0) | 2022.06.26 |