Railroad is not a Train: Saliency as Pseudo-pixel Supervision for Weakly Supervised Semantic Segmentation
Weakly Supervised Semantic Segmentation 분야에서 2021년 CVPR accpet 및 SotA를 달성한 논문이다.
우선 WSSS(Weakly Supervised Semantic Segmentation)의 Process에 대해서 간단히 설명하자면, image에 어떻나 object가 존재하는지만 알려주는 label(이를 image-level label이라고 한다.)을 이용해서, pixel마다 label 정보(이를 pixel-level label이라고 한다.)가 있던 Fully Supervised Semantic Segmentation의 성능을 따라잡으려고 하는 Task이다. 그 중에서 EPS는 WSSS에 속하는 study 결과이다.
논문의 본 github repository의 issue(https://github.com/halbielee/EPS/issues/2)에서 확인할 수 있듯이, new intuition이 없다며 accept를 용납할 수 없다는 반응들이 조금 있다. 이런 반응에는 동의해줄 수 없는 것이, 다른 WSSS 분야의 Related Work만 읽어봐도 image-level label에 다른 supervision을 더하는 방식은 흔하고, 1저자의 답변과 같이 다른 saliency map을 이용한 논문들과는 다르게 co-occuring problem을 제거하는데 집중하고 그에 대한 방법론을 제시하였음을 알 수 있다. 즉, accept 되기에 contribution은 충분하다고 볼 수 있을 것이다. 그리고 그게 불만이면 자기가 쓰면 된다!!!!!!!
Problem
최근 SotA에 해당하는 WSSS model이 다들 그렇듯 이 논문도 시작은 CAM(Class Activation Map)을 구하는 것에서부터 시작한다. 그리고 이 CAM을 refine하는 방식으로 Ground Truth Segmentation에 근접하도록 한다. 이렇게 해서 얻은 결과를 보통 Pseudo Label이라고 부른다.
다만 classification과 segmentation model이 가지고 있는 결정적인 차이, 특히 translation invariance와 segmentation과 classification에 효율적인(혹은 shortcut이 될 만한) image region이 다른 문제 등에 의하여, pure CAM은 Pseudo Label로 사용할만큼의 성능이 나오지 않는다. object의 전체 영역을 커버하지 못하고, 또한 co-occuring(예를들면 기차와 선로는 항상 같이 나오기 때문에, 선로를 기차라고 판별하는 문제가 생긴다.) 문제 등이 발생하곤 한다.

그래서 이 CAM의 결과를 refine하는 방향으로 연구가 진행되어가고 있는 중이고, 2021년에는 EPS라는 논문이 나오게 된 것이다.
Method
EPS는 PFAN이라는 saliency를 구하는 model을 이용하여 saliency map을 이용해서 CAM의 결과를 보정하는 방법을 채용한다.
이는 CAM과 같은 localization map과 PFAN과 같은 saliency map의 차이에 의해서 가능한 방법인데, localization map은 기본적으로 각 class를 구별하기 좋은, discrimitive region에 집중적으로 생긴다. 이는 CAM을 이용한 pseudo label이 object 전체를 차지하지 못하게하고, 또한 정확도를 떨어뜨린다. 그래서 상대적으로 object에 전체적으로 발생하고 object의 boundary가 정확한 saliency map을 두고, CAM을 이용해 saliency map을 추정하고, 이 추정한 결과가 ground truth saliency map과 동일해야한다고 constraint를 두는 방식으로 pseudo label의 정확도를 높이는 것이다.
여기서 saliency inference는 다음과 같은 수식을 통해 수행한다. 자세한 것은 원본 논문을 참조하자.
수식에 대해서 더 설명하자면, Saliency를 inversion한 부분에서는 선로 등의 background를 포함해서 많은 non-object가 포함되어있을텐데, 이를 background CAM에 대해서 따로 loss를 구하기는 번거롭다. 따라서 위의 수식과 같이 background CAM을 어느정도 inversion하는 방식으로 접근한 것이 위의 수식이다.
또한, Ground Truth Saliency Map이 이미지에서 모든 object를 잡아내는 것이 아니기에(예를들면 기차위에 사람이 서있는데, 기차만 잡는 경우도 꽤 있다.), 여기에서 background로 지정된 obejct에 대해서 정확한 CAM을 구하는데 조금이라도 정보를 추가하고자 background CAM을 활용한 것도 있다.
다음은 EPS의 전반적인 구조이다. ResNet-38 등의 Backbone model을 이용해서 background를 포함한 CAM을 prediction하고, 이를 기반으로 saliency prediction을 수행해서 loss를 하나 만들고, 다른 부분에서는 classification이 잘 되었는지 background를 제외한 부분에 대해서 Global Average Pooling을 수행해서
참고로 ResNet-38의 pretrained가 MXNet형태로만 남아있으므로, PyTorch로 변환하는 수고를 해야한다. 이는 EPS 원본 코드에 있으니 그대로 사용하면 된다. 필자도 추후에 어디 공유할 것이다.
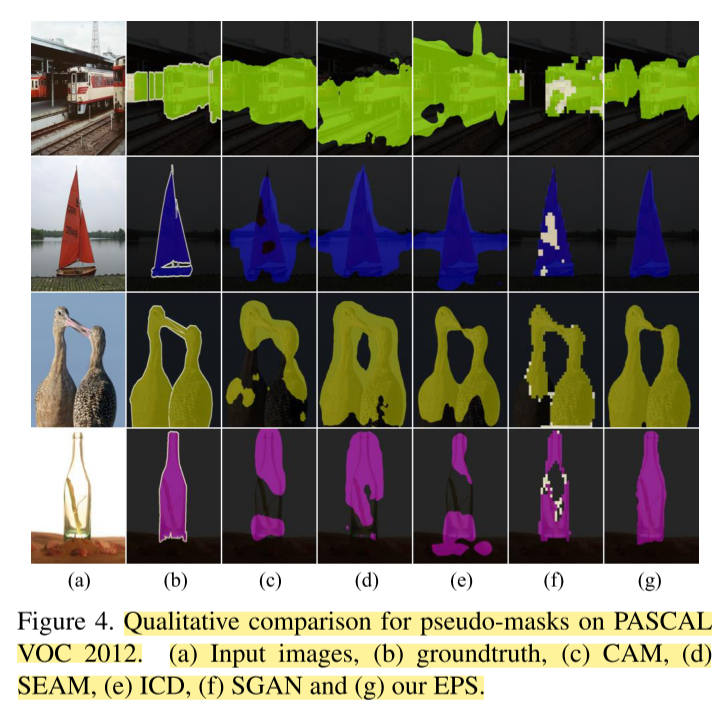
이러한 method에는 단순히 boundary refinement 효과만 있는 것이 아니라, co-occuring을 해결하는 효과가 있다. 위의 기차 그림과 같이, saliency map의 결과물은 보통 background에 해당하는 object(여기서는 선로)등을 표현하지 않게 되기에, 이에 constraint를 두고 학습을 하면 co-occuring 문제를 해결할 수 있게 되는 것을 알 수 있다.
여기서 constraint는 strong constraint가 아니라, total loss function에 추가하는 방식으로 soft constriant로 설정한다.
다음과 같이 Grount Truth Saliency로부터 구한 Saliency loss와 Soft Margin MultiClassification loss를 합하여 total loss를 구하고 Gradient Descent를 수행한다.
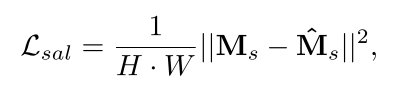
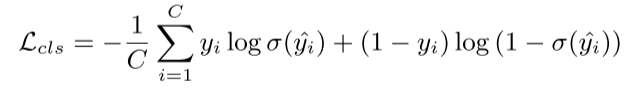
다음은 EPS와 기존 WSSS 방법들을 정성적으로 비교한 것이다.
다음은 논문 원본을 이해하는데 필요한 용어 및 지식들이다.
- things : foreground, stuff : background
- co-occuring pixel : train, rail 등 함께 등장하는 빈도가 높은 things와 stuff
- Image level label은 어떤 class가 있는지를 의미한다.
- 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정 (additional assumptions)을 의미
- 특정 훈련 데이터를 통해 model은 일종의 assumption을 학습하게 되는데, 이 assumption을 가지게 되는 것 자체가 train data를 통해서 inductive(귀납적)으로 얻게된 bias(편향)이라고 보는 것
- 몇 가지 Inductive Bias 예
- Convolutional Network
- Translation invariance = 사물의 위치가 바뀌어도 해당 사물을 인식
- Translation Equivariance = 사물의 위치가 바뀌면 CNN과 같은 연산의 activation 위치 또한 바뀜
- Naive Bayesian Classifier
- Maximum conditional independence = 가설이 베이지안 프레임워크에 캐스팅될 수 있다면 조건부 독립성을 극대화
- Minimum cross-validation error = 가설 중에서 선택하려고 할 때 교차 검증 오차가 가장 낮은 가설을 선택
- SVM
- Maximum margin : 두 클래스 사이에 경계를 그릴 때 경계 너비를 최대화
- Nearest neighbors
- 특징 공간에 있는 작은 이웃의 경우 대부분이 동일한 클래스에 속한다고 가정
- 그외 다른 ML 방법론
- Minimum description length : 가설을 구성할 때 가설의 설명 길이를 최소화 이는 더 간단한 가설은 더 사실일 가능성이 높다는 가정을 기반으로 함
- Minimum features: 특정 피쳐가 유용하다는 근거가 없는 한 삭제
- Convolutional Network
- 딥러닝의 관점에서 Inductive Bias를 이야기해보자면, 딥러닝에서 우리가 흔히 쌓는 레이어의 구성은 일종의 Relational Inductive Bias(관계 귀납적 편향), 즉 hierarchical processing(계층적 처리)를 제공한다.
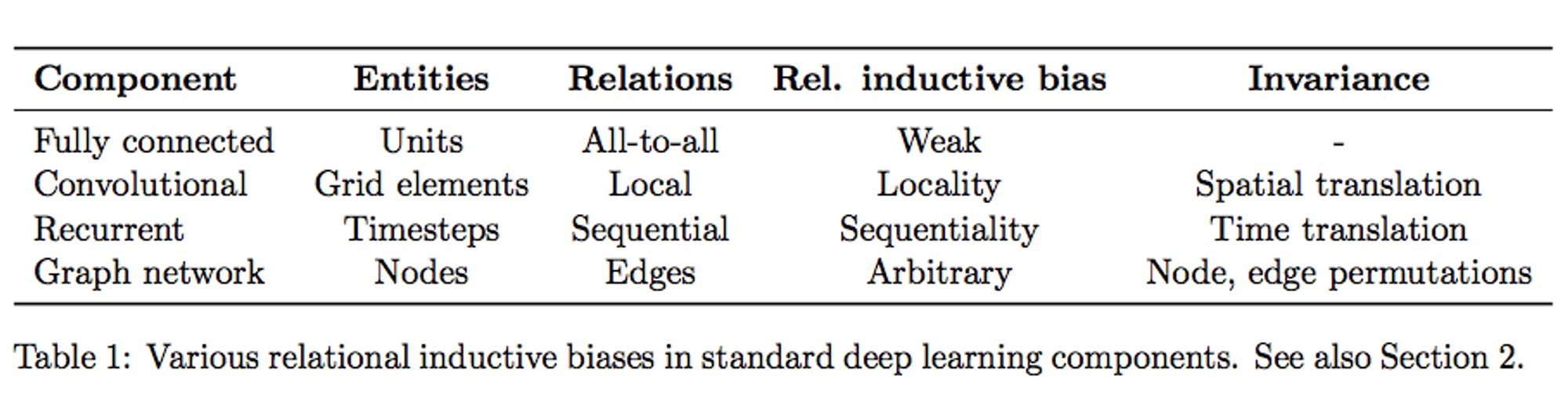
Inductive Bias에 대한 설명은 대부분 이 블로그(Good Explaination Blog)에서 가져왔다.
'AI > Paper Review' 카테고리의 다른 글
| [Paper Review] CLIP^2: Contrastive Language-Image-Point Pretraining from Real- (0) | 2023.09.05 |
|---|---|
| [Paper Review / Transformer]DeiT 리뷰 (0) | 2023.08.21 |
| [Paper Review] DeepLab V2 논문 리뷰 (0) | 2022.08.24 |
| [Paper Review] DeepLab V1 논문 리뷰 (0) | 2022.08.12 |
| [Paper Review] U-Net 논문 리뷰 (0) | 2022.07.28 |