CLIP: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
[2303.12417] CLIP: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data (arxiv.org)
CLIP: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Contrastive Language-Image Pre-training, benefiting from large-scale unlabeled text-image pairs, has demonstrated great performance in open-world vision understanding tasks. However, due to the limited Text-3D data pairs, adapting the success of 2D Vision-
arxiv.org
오늘 소개할 논문은, CLIP을 활용해서 text, image, point cloud 세가지 데이터를 align하는 것을 목표로한다. 본 논문에서는 이 text, image, point cloud 세가지 데이터를 ‘proxy’라고 부른다.
여기서 각 proxy는 다음과 같이 얻는다. 자세한 것은 논문을 참고하자.
- Text는 GT 사용
- Image는 DetCLIP 사용해서 cut
- Point cloud는 image proxy에서 unsupervised segmentation을 사용해서 foreground를 추출한 후, camera parameter를 통해서 영역을 구하거나, 기존의 3D frustum을 만들어내는 방법을 통해 영역을 지정하고 DBSCAN을 통해 point cloud 영역을 최종 설정한다. (자세한 것은 잘 모름…)
아래는 전체 과정

이후에는 text - image - point cloud 세가지를 align하는 학습을 진행한다. text - point cloud는 semantic level language 3d alignment, image - point cloud는 instance level image 3D alignment라고 표현한다. Loss function은 다음과 같다.
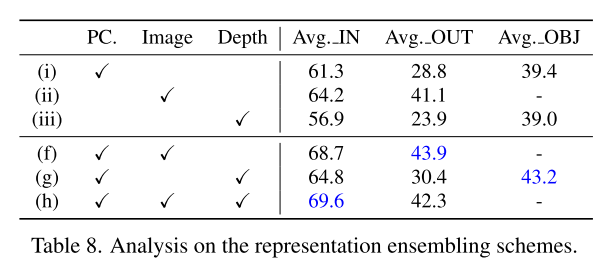
이후로는 기존 방법인 depth를 통한 aligning과 비교하면서 성능 우위를 설명한다. 확실히 결과상 depth가 정보 손실이 크다는 것을 보여준다.
아래는 각 방법론들의 figure.
아래 그림에서 (d)가 본 논문의 방식이다.
아래는 결과. 확실히 outdoor 측면에서 depth를 사용한 방법들 보다 좋은 성능을 보이는 것을 알 수 있다.
'AI > Paper Review' 카테고리의 다른 글
| [Paper Review] Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles 리뷰 (0) | 2023.11.14 |
|---|---|
| [Paper Review] Robust Mean Teacher for Continual and Gradual Test-Time Adaptation 리뷰 (0) | 2023.11.13 |
| [Paper Review / Transformer]DeiT 리뷰 (0) | 2023.08.21 |
| [Paper Review] EPS(Explicit Pseudo-pixel Supervision) 논문 리뷰 (0) | 2023.01.08 |
| [Paper Review] DeepLab V2 논문 리뷰 (0) | 2022.08.24 |