Multiview Equivariance Improves 3D Correspondence Understanding with Minimal Feature Finetuning
Vision foundation models, particularly the ViT family, have revolutionized image understanding by providing rich semantic features. However, despite their success in 2D comprehension, their abilities on grasping 3D spatial relationships are still unclear.
arxiv.org

Overview
이 논문은 Vision Foundation model의 3D awareness를 평가하는데 multiview consistency(equivariance) 등을 평가하고 이를 개선하는 방법을 제안한다. 또한 multiview consistency의 성능 개선의 각 VFM의 본래 task의 성능을 향상시키는 데에도 도움이 된다는 것을 보였다.
전반적인 Contribution은 다음과 같다.
1. Comprehensive evaluation of 3D equivariance capabilities in 2D vision foundation models.
2. Quality of 3D equivariance is closely tied to performance on three downstream tasks that require 3D correspondence understanding: pose estimation, video tracking, and semantic correspondence.
3. Finetuning method that improves the 3D correspondence understanding of 2D foundation models
3D Equivariance Capabilities in 2D Vision Foundation Models
VFM의 3D Equivariance 성능 평가 지표는 Average Pixel Error로 pixel correspondence를 틀린 정도, Percentage of Correct Dense Points로 dense correspondence가 얼마나 맞았는지 정도로 평가한다. 정확하게 무엇인지는 감이 안잡힌다.
실험해본 결과 역시나 DINOv2는 신이라는 결론이다. 3D equivariance 부분에서도 더 나은 성능을 보인다고 한다. 물론 이거 이미지만 봐서는 잘 이해가 가지는 않는다.

3 Tasks Related to 3D Equivariance
각 VFM(DINOv2, DeiT, CLIP, MAE etc.)에 대해서 pose estimation, video tracking, semantic correspondence를 평가한다. 이 세가지 downstream task가 VFM의 3D equivariance power를 평가하기에 적합하다고 주장한다. 이게 납득이 될만한 주장인지는 잘 모르겠다. 각각의 자세한 task 내용은 논문을 더 참고하는 것이 좋을 것 같다.
다음과 같이 대체로 같은 추세의 결과가 나오는 것을 확인할 수 있다. 이를 통해 하나를 잘하면 다른 task도 잘한다는 것을 알 수 있고, quality of 3D equivariance가 downstream task에 큰 영향을 끼칠 수 있다고 얘기한다(?). 그런데 이 부분은 뭔가 설명이 부족하지 않나...

Finetuning Methods for Improving 3D Equivariance
Finetune 방법은 Objaverse dataset에서 서로 다른 두 view를 가져오고 corresponding pixel에 따라 같은 feature가 나오도록 제한하는 loss를 두고 학습하는 것이다. LoRA를 대신하여 작은 Convolution layer를 덧붙이는 방식을 취한다.
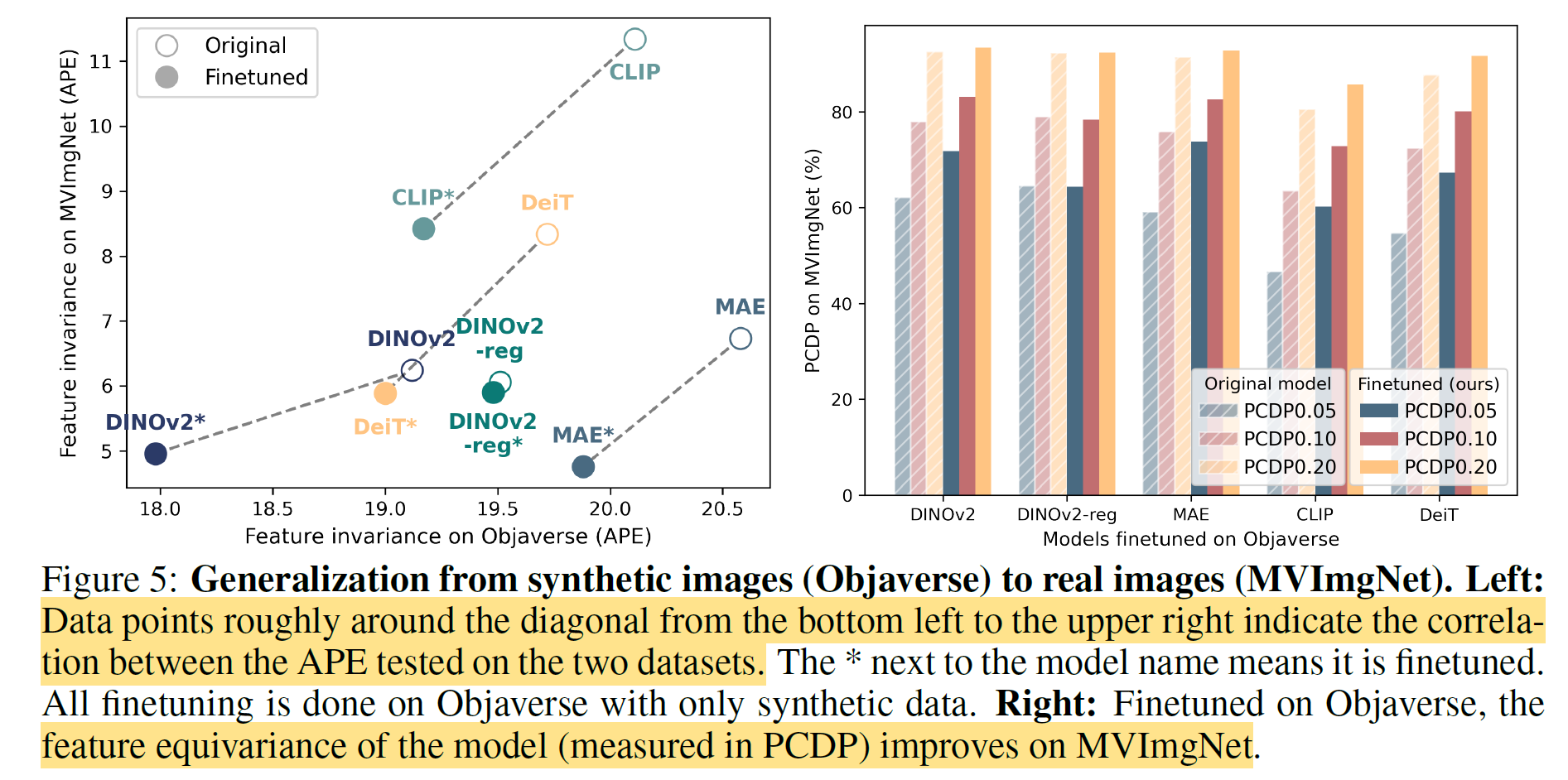
Finetune 이후 결과는 다음과 같다. 그냥 뭐 VFM의 3D equivariance 성능 올랐다는 얘기.
특이한 점은 synthetic data인 Objaverse에서만 학습했는데, real data이 MVImgNet에서도 성능이 대폭 상승한 것을 볼 수 있다. 자연스럽게 sim-to-real 효과도 있음을 보인 것.
DINOv2 기준으로 finetune한 결과의 visualize를 보면, multiview에 대해서 consistent한 feature를 내놓았음을 알 수 있다.

finetune 이후 각 downstream task의 성능도 높아졌음을 언급한다. 어느 정도는 이것 자체도 3D equivariance와 각 downstream task가 관계가 있음을 보이기도 하는 것.


심지어는 이게 하나의 object만 학습하는 one-shot setting을 가져가도 성능이 꽤 크게 오른다는 점이다. 즉 3D data를 굳이 크게 가져갈 필요는 없는 것

심지어 training iteration도 많지 않아도 된다는 것을 확인할 수 있다.

DINO feature를 활용한 Wild Gaussian, LERF에서도 finetune한 feature를 사용했더니 성능이 상승했다.

Other Analysis
1. Convolution layer를 하나 넣는 것은 원래 ViT가 low resolution patch를 기반으로 동작한다는 점을 보완한다. convolution layer를 하나만 추가하면 dense per-pixel feature를 interpolation하게 됨으로써 low resolution patch의 이웃간의 정보를 결합할 수 있게된다. 이게 더 도움이 된다는 주장... 납득은 안됨.
2. MVImgNet보다 Objaverse에서 finetune하는 것이 더 성능이 좋다고 한다. VFM은 생각보다 syn-to-real gap이 없다고...
3. Scene level dataset이 VFM의 3D equivariance를 높여주지는 못한다고 한다. 오히려 3D object 자체가 reasoning information은 충분히 있다고... scene level에서는 background의 존재가 학습에 방해가 된다고 한다. 납득은 안됨.