https://arxiv.org/abs/2404.08636
Probing the 3D Awareness of Visual Foundation Models
Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tas
arxiv.org
Overview
VLM을 비롯해서, 여러 Vision Foundation model (DINOv2, MiDAS etc.)의 3D awareness를 평가하고자 한 논문이다.
이를 위해 크게 두가지 실험을 수행했다.
1. Single Image Surface Reconstruction: depth, normal prediction by probing
2. Multiview Consistency: pixelwise correspondence prediction w/o probing
Single Image Surface Reconstruction
대체로 CLIP과 같은 language-based training을 거친 모델들이 depth와 normal prediction이 잘 안된다고 한다. 이외에는 DINOv2와 StableDiffusion이 가장 잘 된다고 한다.

모델 단위 성능 correlation을 확인해보면 대체로 depth 잘하면 normal prediction도 잘한다고 한다. 물론 이미지 단위나 픽셀 단위로 확인하려고하면 correlation이 낮아지는 걸 확인했기에 주의해야한다고 살짝 언급되어있다.
Multiview Consistency
3D awareness를 평가하기 위해서는 multiview에서 같은 pixel임을 아는 것이 가장 중요한 평가 방법이다. ScanNet과 NAVIS 데이터셋에서 평가를 진행했고, 120도 이내의 촬영각의 데이터만을 활용했다고 한다.
대부분의 경우 viewpoint가 많이 변하면 크게 성능이 떨어졌다고 한다. 특히 SAM과 StableDiffusion은 viewpoint가 일정 영역에서 조금만 벗어나도 성능이 급감하는 것을 확인했다고.
논문 내에서의 결론은 VFM이 아직 3D consistency까지는 확보하지 못했다는 결론.

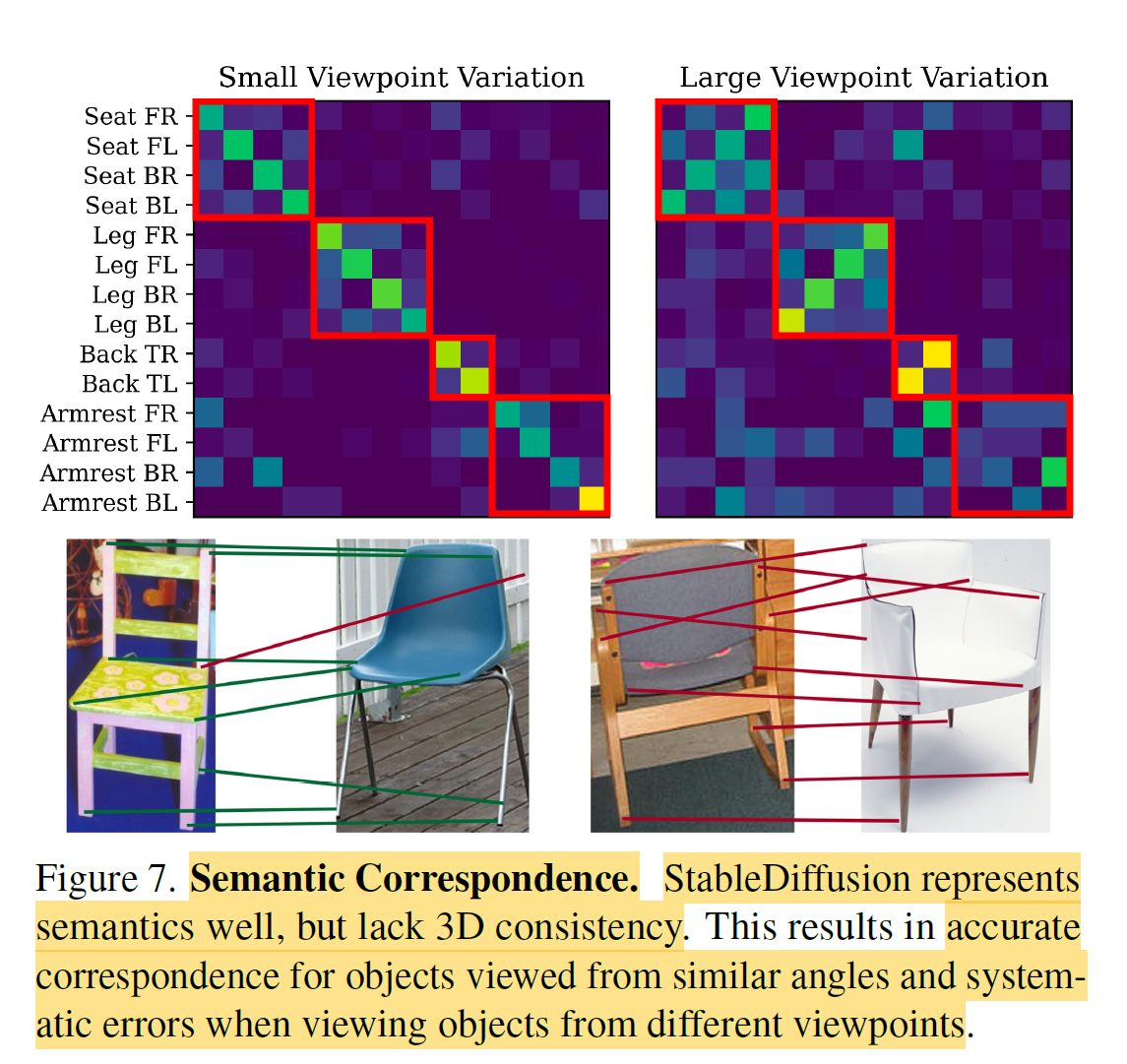
또한 StableDiffusion 기준으로 confusion matrix 결과를 확인해보았을 때, small viewpoint에서는 variation이 크지 않은 것으로보아 semantic-2D prior가 강하게 학습된 것을 확인할 수 있다고 한다. 맞나?
Analysis
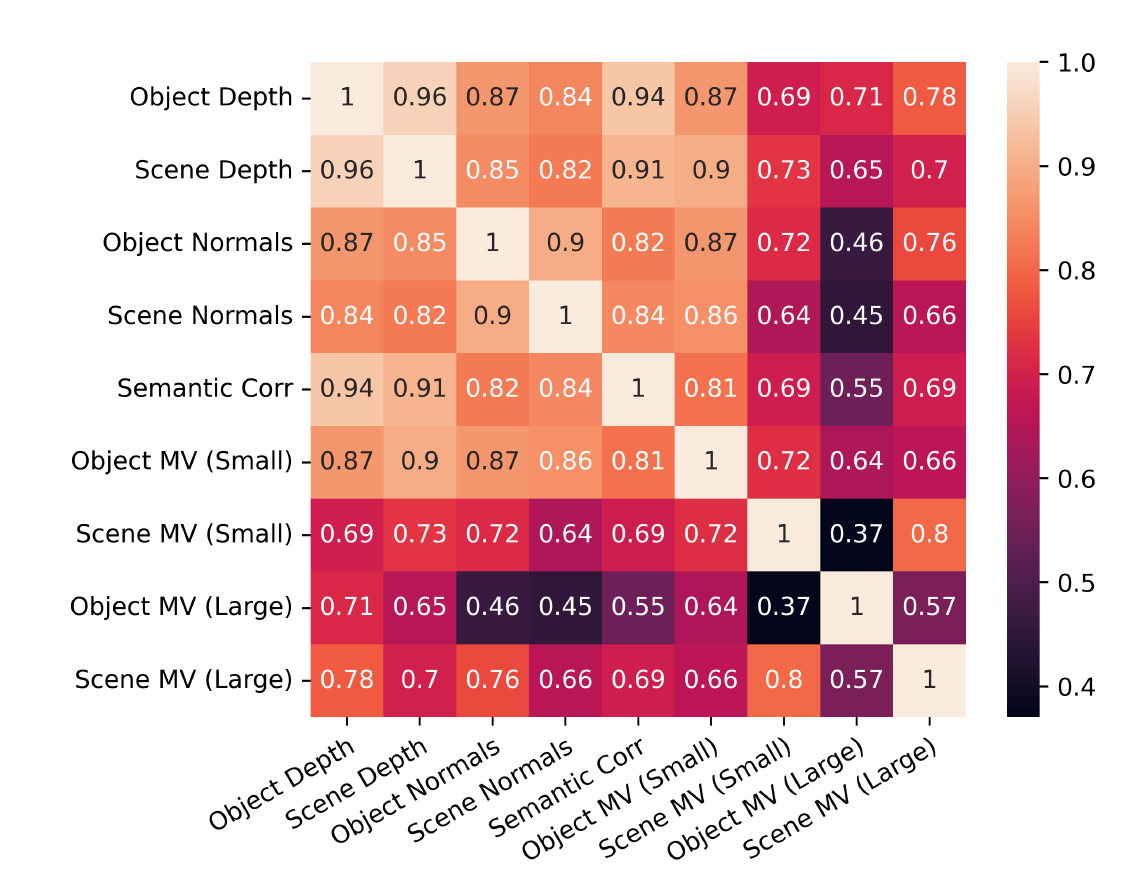
Task에 따른 Pearson correlation을 확인해보면, depth/normal prediction과 같은 single view task가 semantic correspondence를 예측하는데 관련이 있다는 것을 확인했다고 한다. 그에 반해 crossview consistency는 semantic correspondence과는 상관관계가 떨어진다고 한다. 다른 single view task와도 마찬가지고.