반응형
Introduction
Temporal Action Detection은 특정한 Action의 시작과 끝을 찾는 task를 의미

- Action이 종료되기 직전과 직후는 상당히 유사해서, end time을 선언하기 어려움
- Action이 언제든 발생할 수 있어서, 영상 자체에서 action이 비중이 낮아서 예측이 어려움
- 아래 설명은 Fully Supervised Learning 기준으로 설명
Terminology
- Annotation = class label과 start time, end time
- Temporal Proposal = model에서 제안하는 class label과 start time, end time
- Temporal IoU = tIoU = predicted interval $I_p$와 Ground Truth interval $I_g$를 통해 계산

- Temporal Proposal Labeling = tIoU가 정해진 threshold보다 크면, 이를 positive.
- ground truth가 여러 proposal과 겹치는 경우 가장 큰 confidence score를 보이는 proposal만 true positive
- Action score = action이 있을 확률
- startness / endness = action의 start/end 확률
- Action Completeness Score = proposal과 ground truth가 가진 가장 높은 tIoU
- Action Classification Score = proposal을 encoder에 넣었을 때 나온 classification score
Video Feature Encoding
- 보통 video를 일정한 크기로 자른 snippet을 사용한다.

- snippet에 대해서, RGB frame과 optical flow를 사용해서 각각의 모델로 넣거나,
- 이 둘을 stack해서 동시에 활용하거나,
- 3D convolution을 통해 snippet을 동시에 다루거나 한다.
Action Detection with Full Supervision
- Anchor based : frame 길이가 지정된 상태에서 multiscale로 접근해서 feature extracting
- temporal domain에서의 정확도가 떨어짐
- Recall이 상대적으로 낮음

- Multiscale을 활용하는 방법도 많다.
- 각 proposal마다 random sample해서 encoder에 집어넣는다. 이러면 rich feature를 잃어버린다.
- 3D RoI Pooling을 시도. Faster RCNN과 동일한 접근. 어떤 물체에 대해서는 RoI가 너무 크거나/작을 수도 있다.
- Receptive Field size를 다루는 방법도 여러 가지이다.
- Multi-tower Netwrok는 각 anchor-size마다 따로 CNN을 둔다. 그렇게 anchor-size마다 receptive field가 다양하도록 dilated convolution을 사용
- Temporal Feature Pyramid Network : 다양한 reolution의 feature map을 동시에 활용한다. lower level feature는 짧은 action, high level feature는 long action을 찾도록 한다.
- U-shaped Temporal Feature Pyramid Network : U-net 처럼 여러 temporal resolution에 대해서 혼합하여 동시에 고려되도록 한다.
- non-Anchor based : start, end probability를 구하여 예측, 이후에 feature extracting
- action score등을 통해 start, end probability를 예측
- boundary score를 구해 start, end probability를 예측
- start, end를 찾는 과정에서 local context만 사용하는 경향 -> noise에 취약함
- 대체로 이런 Anchor-free method가 더 좋은 성능을 보인다.

- Anchor & non-Anchor combination : 이 둘의 장점을 극대화하기 위한 시도.
- initial proposal에 conv filtering -> start, end detection은 probability로
- Temporal feature pyramid networks, TFPN은 anchor-based로 여러 크기의 segment를 만들고, non-anchor-based로 fine-level frame actioness를 판단한다.
- Proposal Feature Extraction에서는 anchor size마다 따로 CNN을 두거나 temporal feature pyramid가 사용되는 것이 효과가 좋다.
Common Loss Functions
- Actioness loss : binary cross entropy

- Action completeness loss : L1/L2 loss for positive proposal

- Action overlap loss : Action completeness loss의 변형. GT와의 겹침이 커지도록 한다.

- Action classification loss : cross-entropy를 사용. 어떤 action인지 구분

- Action regression loss : start, end를 예측

Modeling Long-range Dependencies
Long squence의 dependency를 modeling하기 위해
- RNN
- hidden state를 통해서 이전 예측을 활용하여 정보를 인코딩한다

- hidden state를 통해서 이전 예측을 활용하여 정보를 인코딩한다
- Graph NN
- node = temporal feature, edge = similarity 등으로 설정해서 feature extraction

- node = temporal feature, edge = similarity 등으로 설정해서 feature extraction
- Attention mechanism, Transformer
- video 내의 action들이 nonsequential한 경우 효과적
- Graph NN 혹은 Transformer architecture를 통해 long-range를 커버한 방법이 성능이 더 좋다.
Spatio-temporal Action Detection
temporal action 뿐 아니라 어디서 action이 일어나는지도 맞추는 task
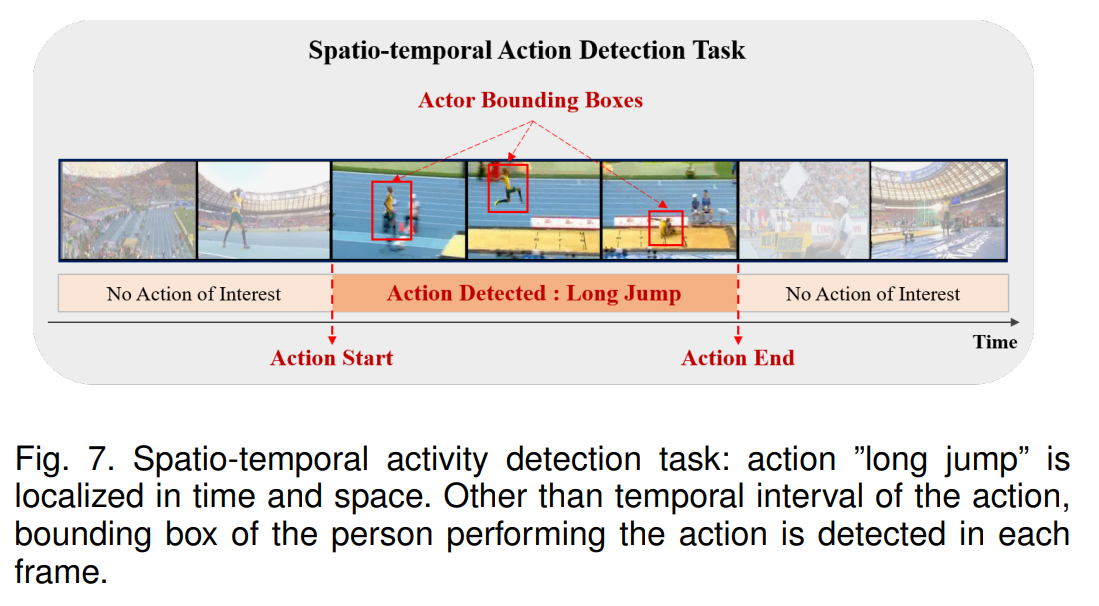
- Frame-level Action Detection
- RCNN과 같이 action이 temporal, spatio에서 어떻게 일어나는지 propose
- 그 다음 그 위치가 적절한지 refine한다
- temporal property가 최대로 활용되지 못함
- Clip-level Action Detection
- 짧은 수준의 video snippet을 받아서 temporal information을 활용
- Modeling Spatio-temporal Dependency
- Action과 context(object)등의 상관관계를 모델링한다.
- GNN, attention mechanism 등을 활용
- 이를 통해 video 내에 요소를 각 video clip과 연관지어, long-range에서의 prediction을 효과적으로 수행
Datasets
- THUMOS14
- 220 train sample, 213 test sample
- 20 classes
- 70% of all frames are labeled as background
- ActivityNet
- 19, 994 videos in 200 classes
- training, validation, and testing, by 2:1:1

- Breakfast
- 1712 videos for breakfast preparation
- 10 classes

Evaluation Metrics
- Temporal Action Detection
- Average Recall (on multiple mIoU threshold)
- mAP (on multiple mIoU threshold)
- Spatio-temporal Action Detection
- frame-AP : frame별로 precision-recall curve의 아래 영역
- video-AP : 전체 frame에 대해, action bounding box에 대해서 precision-recall curve의 아래 영역
반응형