본 포스팅에서는 'Closing the Loop for Robotic Grasping : A Real-time, Generative Grasp Synthesis Approach'를 리뷰한다.
Paper Link
https://arxiv.org/abs/1804.05172
Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach
This paper presents a real-time, object-independent grasp synthesis method which can be used for closed-loop grasping. Our proposed Generative Grasping Convolutional Neural Network (GG-CNN) predicts the quality and pose of grasps at every pixel. This one-t
arxiv.org
Abstract
GG-CNN은 받아들인 이미지의 각 pixel 마다 grasp의 quality(얼마나 잘 잡을 수 있는지)와 pose of grasp(잡는 각도 등의 자세)를 결정하는 model이다.
받아들이는 이미지는 기본적으로 depth image(각 pixel마다 거리 값이 주어지는 이미지)이고, discrete sampling of grasp candidate를 구하지 않음으로써 computing speed가 빨라지고 기존의 limitation을 해결하였다.
다른 SotA와 비교했을 때 동등한 성능을 보이면서, 더 작은 model로 구현되었다.
Introduction
로봇에서 물체를 잡는 문제, 즉, grasping 문제에서는 기본적으로 본적이 없는 물체의 grasp point를 선정하는 것이 주요 task이다.
기존의 Deep Learning Grasp 연구는 sample & rank 'grasp candidate' 방식이었다.
이 방식은 다음과 같은 특징이 있다.
- 주로 open loop grasp robot에서 사용됨
- 정밀한 camera calibration, robot control을 요구한다.
본 논문에서 제시하는 접근 방법은
- 즉각적으로 antipodal grasp pose(양쪽에서 잡는 것을 의미한다.)와 quality measure를 모든 pixel에 대해서 계산한다.
- 그리고 이 방법론은 closed loop control로 구동 가능하며 dynamic environment에 대해서도 성능이 좋다.
- 기존의 grasp candidate를 sample하는 method와는 차이를 두기 위하여 논문 제목에 generative라고 이름 붙였다고 한다.
참고로 closed loop에서는 다음과 같이 feedback 과정을 거쳐서 robot control을 하게 된다.

기존 grasp model에 비교해서 두가지 장점이 있다.
- grasp candidate를 sampling하지 않고, grasp pose를 모든 pixel에 대하여 generate한다.
- 이걸 뭐 sliding window, bounding box를 사용하는 것에서 fully convolutional network를 통해서 semantic segmentation을 수행하는 발전에 비유함.
- 다른 CNN based Grasping model과 비교해서 parameter의 수가 매우 적다.
실험 조건은 다음과 같다.
- Knova Mico라는 universal robot을 사용했다.
- static한 물체, dynamic한 물체, 그리고 여러 개의 물건과 쌓여있는(cluttered) 물체를 집는 과정을 거쳤다.
- 83%의 adversarial geometry에 대한 grasp 성공율, 88%의 household object에 대한 grasp 성공율을 보였다.
Related Work
기존의 연구에 대한 설명이 조금 필요할 것 같다.
Grasping 연구 전반에 대하여
크게 analytic methods와 empirical methods로 나뉜다.
Analytic methods의 경우, 수학 - 기구학적인 방법과 kinematics, dynamics를 이용해서 grasp가 stable하게 실시되도록 조정하는 방법론이다. 하지만 현실에서는 noise 때문에 구현하기 어렵다.
Empirical methods는 model을 이용하고 경험 기반의 접근 방법을 사용한다. 기존의 연구의 경우, 정해진 물건에 대해서 grasp point를 정했다.
- 이때, object model 혹은 shape에 대해서 정할 수도 있고,
- object class나 object parts에 대해서 정할 수도 있다.
당연히 새로운 물체에 대해서 grasp를 일반화하기 어렵다는 문제가 있다.
Deep Learning의 대두 이후에는 대부분의 grasping model이 다음과 같게 되었다.
- image나 point cloud로부터 sample된 grasp candidate를 classifying한다.
- CNN을 통해서 rank를 매긴다.
- best grasp candidate가 정해지면 robot은 grasp를 open loop로 수행한다.
open loop에 대한 설명은 아래에 기재하였다. execution time이 큰 것이 사실 open loop를 사용하는 원인이다. 논문 발표 당시 시점으로, 보통 detection을 할 때 sliding window를 통해서 이산적인 구간 혹은 회전에 대해서 grasp candidate를 구하게 되는데, 이는 큰 연산량을 요구하게 된다.
이를 해결하기 위해서 grasp candidate를 pre-processing하거나 pruning하거나, grasp candidate set의 grasp quality를 예측하거나, 몇 개의 potential grasp를 무시하는 방법이 있었고, 단 하나의 best grasp pose로 regress하는 deep CNN 또한 있었으나, 이 방법은 기존의 possible한 grasp의 평균을 결과로 내보내는 경향이 있었다. 또한 이 결과는 valid grasp가 아닌 경우가 많았다.
이러한 문제를 해결하기 위해서 'directly generating grasp poses for every pixel in an image'를 수행한다.
Closed Loop Grasping
Closed Loop robot은 feedback을 통하여 동작을 지속적으로 수정해나가기 때문에, dynamic한 환경에서 적합하고 정밀한 수준의 camera calibration과 position control이 불필요하다. 이를 servoing이라고도 하는데, image를 통해서 이런 작업을 수행하면 visual servoing이라고 한다. 이 논문에서 수행하는 것이 바로 이것이다.
하지만, object detection이나 pose estimate에 사용되는 image가 모두 hand-crafted(일정히 처리되어 있어서 로봇이 사용하기에 현장감이 적다는 의미인 듯 하다.)되어 있어서, online grasp synthesis(본 논문에서 하려고 하는 task. 바로 grasp point를 찾아 만드는 것)는 하지 않으며, 대신 이미 정해진 goal grasp pose로 수렴하게 된다. 이렇게 되면 unknow object를 grasp하려는 task는 불가능하다.
최근의 CNN based controller가 deep learning과 closed loop grasping을 융합하려는 시도를 보였다. 이 경우, grasp synthesis를 하기보다는, controller를 학습하는데, 이 controller는 특정한 command가 실행되었을 때, grasp의 평균 quality와 distance to a grasp을 mapping한다.
Benchmarking for Robotic Grasping
이 시점까지 Robot Grasping에 대한 기준이 되는 dataset이 없었던 모양이다. 그래서 본 논문에서 적당한 것들 골라서 만들었다고 한다. 이 부분은 디테일이 너무 많아서 생략한다.
Grasp Point Definition
이번에는 grasp를 정의해보자. 여기서 antipodal grasp는 서로 대칭되게 반대편에서 맞잡는 것을 의미하고, 로봇팔을 기준으로 수직으로 집는 것을 본 논문에서는 가정했다.

여기서 grasp는 함수로 다음과 같이 정의된다. 이 때, grasp는 xy평면에 대해서 수직으로 수행된다.
$$g = (p, \phi, w, q)$$
여기서 $p = (x,y,z)$는 gripper의 중심 위치이다. 그리고 $\phi, w, q$는 각각 gripper의 z축에 대한 회전량, 최소한 필요한gripper의 width, 그리고 grasp에 대한 성공 확률을 의미하는 quality measure이다.
gripper width를 포함함으로써 prediction의 정확도가 올라가고 성능 또한 상승했다고 한다.
2.5D depth image를 $I = R^{H \times W}$로 정의한다. 이 때, 이 image $I$에서 본 grasp는 다음과 같이 표현된다.
$$\tilde{g} = (s, \tilde{\phi}, \tilde{w}, q)$$
여기서 $s = (u,v)$는 image coordinate에서의 중심점이다. 그리고 $\tilde{\phi}, \tilde{w}, q$는 각각 camera의 reference frame을 기준으로 회전한 정도이고, image coordinate에서의 최소 요구 grasp width이고, grasp에 대한 성공 확률을 의미하는 quality measure이다.
이 image space에서의 grasp를 의미하는 $\tilde{g}$는 world coordinate에서의 grasp $g$로 변환할 수 있다.
다음과 같이 행한다.
$$g = t_{RC}(t_{CI}(\tilde{g}))$$
여기서 $t_{RC}$는 camera frame에서 world frame으로의 transformation이고, $t_{CI}$는 2D image coordinate에서 3D camera frame으로의 transformation이다. 이 transformation은 camera intrinsic parameter와 robot과 camera 사이의 이미 알려진 calibration에 기반하여 결정된다.
image space에서의 set of grasp를 grasp map이라고 한다. 함수로서의 표현은 다음과 같다.
$$G = (Φ,W, Q) ∈ R ^ {3×H×W}$$
여기서 $Φ, W, Q$ 는 $R^{H×W}$이고, 이들은 각 pixel에서의 $\tilde{φ}, \tilde{w}, \tilde{q}$ 값을 저장한다.
grasp candidate를 생성하기 위해서 input image를 sampling하는 것이 아니라, depth image $I$를 받아서 곧바로 image space에서의 grasp $\tilde{g}$를 각 pixel에서 생성하고 싶다.
이를 위하여 depth image에서 grasp map (image coordinate에서의)을 output하는 function $M$을 정의해야한다.
$$M(I) = G$$
여기에서 $G$를 통해서 image space에서의 최상의 visible grasp를 찾을 수 있다. 이때의 수식은 $\tilde{g}^* = max_{Q} G$ 이다. 그 후 앞서 보인 $g = t_{RC}(t_{CI}(\tilde{g}))$ 변환을 통해서 world coordinate 기준으로 best grasp인 $g^*$를 구한다.
Generative Grasping Convolution Neural Network
앞서 말한 $M(I) = G$을 근사하는 데에 Neural Network를 사용한다. $M_{\theta}$는 Neural Network가 weight $\theta$로 근사한 function임을 의미한다.
$M_θ(I) = (Q_θ, Φ_θ,W_θ) ≈ M(I)$임을 알 수 있고, 이 때의 weight는 training set of input image $I_T$, 근사 대상인 함수 $M$의 output 이어야할 $G_T$ 사이의 L2 loss를 사용하여 구할 수 있다. 즉, loss function을 다음과 같이 새로 작성해주어야 한다.
$$θ = argmin_θ L(G_T , M_θ(I_T))$$
$G$는 Cartesian point $p$에서 수행한 grasp를 구성하는 모든 parameter를, 모든 pixel에 대하여 estimate한다. 앞서 말한 것 처럼 grasp map $G$는 세 개의 parameter $Q, Φ, W$로 구성되는 데, 이들은 모든 pixel에서의 회전량, grasp quality, width를 담고 있으므로, 일종의 image라고 볼 수 있다.
여기서 $Q$는 각 point $(u,v)$에서 grasp의 quality(성공 확률)을 나타내는 이미지이다. 각 pixel에서의 값은 0부터 1 사이이고, 1이면 성공한다는 뜻이다.
$Φ$는 각 point에서의 angle of grasp를 의미하는 이미지이다. 이 때 antipodal grasp가 $±\frac{\pi}{2}$의 구간 내에서 대칭으로 작용하므로 angle은 $-\frac{\pi}{2}$부터 $\frac{\pi}{2}$까지이다.
$W$는 각 point에서의 gripper width of a grasp이다. depth의 불변성을 위해서, 값은 0에서 150 pixel 까지로 제한한다. $W$는 depth camera의 parameter와 measured depth를 통해서 physical measurement로 변환할 수도 있다.
Training
Cornell Grasping Dataset을 만들어서 사용하였다. 5110 human-labelled positive와 2909 negative grasps로 구성되어 있다. 각 image마다 여러 개의 grasp가 label 되어 있다. 이를 또 random crop, zoom, rotation을 하는 등의 data augmentation을 수행하고 이들을 모두 grasp map image $G_T$에 포함시켰다.
Cornell grasping Dataset은 antipodal grasp를 직사각형으로 표현한다. 이 직사각형은 gripper의 position과 rotation을 내포하고 있다.
여기에서 image space에서의 grasp map $G$를 구하려면, 직사각형을 3분할 한 것 중에서 중간의 것을 image mask로 이용해서 gripper 중심의 position을 나타낸다. 이 image mask를 이용해서 training image의 각 section을 update할 것 이다.
training 단계에서는 positive labelled grasp만 사용하였고, 다른 부분은 모두 invalid grasp로 처리했다.
$Q_T$는 grasp가 가능한 area에서만 1의 value를 가지고, 다른 pixel에선 모두 0이다.
$Φ_T$의 경우 angle을 표한하는데, $± \frac{\pi}{2}$에서의 불연속성을 제거하기 위해서 단위 원 위의 한 점을 가리키는 vector component를 통해서 angle을 표현했다. 각 component마다 -1부터 1까지의 값을 갖는다.
또한, 전에 말한 전체 구간 $± \frac{\pi}{2}$에서 symmetric하므로, 하나의 motion만 구하기 위해서 두 개의 component $sin(2Φ_T)$, $cos(2Φ_T)$를 구하는 것으로 한다. 이렇게 하면 값이 unique해지고, $± \frac{\pi}{2}$에서만 symmetric 해진다.
width $W_T$는 최대 150으로 계산한다. 이는 앞서 말한 것처럼 width of the gripper를 의미한다. 이를 150으로 나눠서 range를 0부터 1까지로 만들었다. physical gripper width는 camera parameter와 measured depth를 통해서 계산할 수 있다.
종합하면, dataset에서 구하게 되는 변수는 다음 figure와 같을 것이다.

Depth Input에 대해서, 이미 dataset에 noise가 많으니 noise를 추가할 필요는 없다. 또한 invalid한 value는 OpenCV를 이용해서 복원했다고 한다. 또한 depth image를 mean 값으로 빼줌으로 써 0으로 centering했다고 한다. 이러면 depth invariance가 일어난다고...
Network Architecture
다음은 GG-CNN의 Network Architecture이다. 3번의 Convolution이후, 3번의 Transpose Convolution을 진행하여 feature map을 다시 확대 시킨다.

GG-CNN은 fully conolutional architecture이다. GG-CNN은 grasp map $G_θ$을 input depth image $I$로부터 근사해낸다.
즉, GG-CNN은 $M_θ(I) = (Q_θ, Φ_θ,W_θ)$을 fitting하게 된다. $I, Q_θ, Φ_θ,W_θ$는 모두 $300 \times 300$ pixel image로 표현된다.
여기서 각도 $2Φ_θ$는 두 개의 이미지로부터 구하고, 값은 계산식 $Φ_θ = \frac{1}{2} arctan \frac{sin(2Φ_θ)}{cos(2Φ_θ)}$을 이용해서 구한다.
최종적으로 모델은 62420개의 parameter를 보유하게 되고, 기존의 다른 모델보다 빠른 성능을 내게 된다.
Setting for Experiment
Physical Components
- Kinova Mico 6DOF robot
- 15mm 이하의 높이의 물건은 집을 수 없다.
- Intel RealSense SR300 RGB-D camera
- mounted to the wrist of the robot, 80 mm above the closed fingertips
- inclined at 14º towards the gripper
- 150mm 이내에서는 정확한 depth 측정이 안된다. 적외선 센서와 카메라를 분리시켜서 depth image에 그림자가 생긴다고 한다.
- closed loop grasping trail에서 70mm 정도의 depth일 때, grasp pose를 update하는 것을 멈추었다.
- black 혹은 reflective object에서는 depth data를 제대로 뽑지 못한다.
- Ubuntu 16.04 with a 3.6 GHz Intel Core i7-7700 CPU and NVIDIA GeForce GTX 1070 graphics card
Test Objects
- Adversarial Set
- Household Set
Grasp Detection Pipline
3 stage로 구성된다.
- image processing
- GG-CNN evaluation
- computation of grasp pose
우선 image processing부터 살펴보자.
depth image를 $300 \times 300$의 크기로 자른다. 그리고 OpenCV를 통해서 invalid depth를 복원한다.
그 다음, GG-CNN을 evaluation한다. GG-CNN은 grasp map $G_θ$을 출력한다. $Q_θ$(Neural Network가 추론한 quality)를 가우시안 커널로 filtering하여 outlier를 제거하고 $G_θ$의 local maxima가 더 robust grasp가 가능한 region으로 수렴하도록 한다.
그 후, $\tilde{g_θ^*}$를 구한다. 이는 maximum pixel $s^*$을 $Q_θ$로 구하고, rotation과 width를 $Φ_{θ|s^*}$ and $W_{θ|s^*}$로 부터 구한다. 그렇게 해서 $g_{θ}^*$(Neural Network에서 구한 world coordinate의 최적 grasp)를 앞서 보인 다음과 같은 식으로 구할 수 있다.
$$g = t_{RC}(t_{CI}(\tilde{g}))$$
Grasp Execution
open loop system과 closed loop system에 대해서 모두 실험하였다.
open loop system에서는 하나의 viewpoint에서 grasp pose를 계산하고 실행한다.
closed loop system에서는 visual 정보를 통해서 feedback을 받아서 servoing을 한다. closed loop system은 dynamic environment에 대해서도 적용하였다.
open loop grasping
- 350mm 위에서 camera를 놓는다.
- 그리고 depth image를 찍고,
- gripper tip은 집을 대상의 170mm 위에 배치하고, 수직으로 내려간다.
- grasp pose가 만족되거나 충돌이 발생하면 멈춘다. 그리고 lift를 실행한다.
- 그리고 grasp 성공 여부에 따라서 기록을 진행한다.
closed loop grasping
- Position Based Visual Servoing (PBVS) controller를 구현하였다.
- camera는 400mm 위에 설치되어있다.
- Depth image를 촬영하고, grasp pose를 계산한다.
- 이때, 여러 개의 비슷한 정도의 good grasp가 있을 것이다. 서로 간의 혼동을 피하기 위해서, $G_θ$ 세 개의 good grasp를 선정하고, 직전 iteration에서의 grasp pose와 가장 가까운 것을 집는 것으로 결정한다.
- robot movement에 비해 control loop가 빨라 frame(depth image의 frame을 의미하는 듯 하다.) 간 큰 변화가 없을 것으로 보인다한다.
- system은 매 grasp attempt마다 $Q_θ$의 global maxima를 track한다.
- poses of the grasp를 $T_{g^∗_θ}$라고 하고, gripper fingers $T_f$라고 한다. 이들을 6D vectors로 표현하는데, 여기서 6D vector는 $x,y,z$ 세개의 position과 roll, pitch and yaw와 같은 Euler angles를 포함한다.
- 즉, $(x, y, z, α, β, γ)$로 poses of the grasp와 gripper finger를 표현한다.
- 그리고 이를 이용해서 robot의 end-effector의 6D velocity signal를 생성한다. 그 식은 다음과 같다.
$$v = λ(T_{g^∗_θ} − T_f )$$
$λ$는 gripper가 grasp pose로 수렴하게 하는 6D velocity scale이다.
- 이 velocity를 이용해서 control을 수행하여 gripper finger를 직전 과정에서 계산된 gripper width로 이동시킨다.
- 이 과정에서 grasp pose에 도달하거나 충돌이 발생하면 멈춘다.
- gripper는 닫히고, lift를 시도한다. 성공 여부를 기록한다.
Object Placement
object의 pose에 따른 편향을 없애기 위해서 박스에서 object를 흔들어서 바닥에 흩뿌리는 식으로 task를 수행했다. workspace의 공간은 $250 \times 300$mm라고 한다.
Experiment
본 논문 당시 grasp task에 대한 일정한 dataset이나 measure가 없었다. 그래서 본 논문에서는 기존의 논문의 실험을 기준으로 하여 grasp object를 최대한 reproducible하게 선정하고, 새로운 dataset를 개발하였다.

또한,
- 정지된 단일 물체
- 운동 중인 단일 물체
- 정적인 잡동 사니 중 목적 물체
- 운동 중인 잡동 사니 중 목적 물체
에 대해서 grasp를 시도하였다. 이 때, 잡동 사니 물체에 대해서는 사전 학습되지 않은 상태였다.
또한, simulated kinematic error가 robot control에 있는 상황에서도 grasp를 시도하여 closed loop grasping의 장점을 증명하였다.

결과는 대략 다음과 같다.

Robustness to Control Error
Baxter Research Robot, Lenz et al.에 의하면 20mm 정도의 positioning error는 항상 있는 것이라고 한다. 그래서 closed loop system을 사용하면 이런 오차를 조금이라도 줄여서 정확한 positioning이 가능하다.
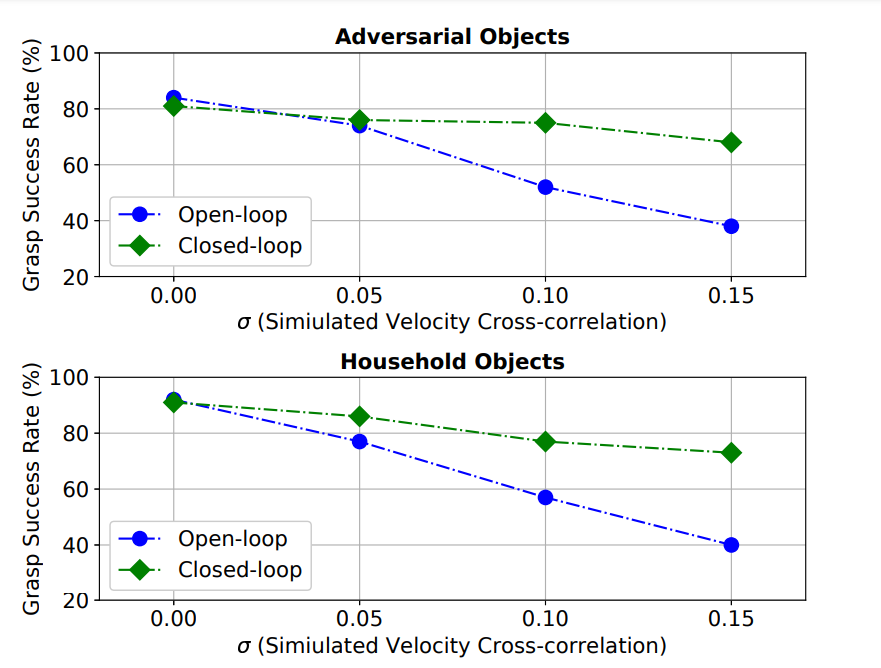
본 논문에서는 inaccurate kinematic model of robot을 cross-correlation을 도입하여 다음 velocity를 정의해 simulation 했다.

$c ∼ N(0, σ^2)$이고, 각 grasp attempt의 시작 시 sample된다. 본 논문에서의 noise model은 robot의 kinematic model과는 독립적이라서, 다른 로봇에서도 적용 가능하고, end-effector positioning의 관점에서 deterministic effect가 있다.
open/closed loop system에서 $σ = 0.0, 0.05, 0.1, 0.15$을 적용해서 실험했다.
open loop의 경우, end effector의 정밀도가 다음과 같아졌다고 한다. $∆x = ∆y = ∆z · N (0, σ^2 ) = N (0, ∆z^2σ^2 ); ∆z = 170 mm$
그리고 Fig 8을 보면 closed loop control이 open loop보다 더 나은 정확도를 보임을 알 수 있다.
Conclusion
GG-CNN model이 기존의 Grasp Model보다 성능이 뛰어났다.
- grasp pose를 depth image로부터 바로 생산해낸다.
- 기존 model에 비해서 작은 parameter로, 빠른 연산 수행이 가능하다. 그 결과 closed loop control이 가능하다.
- 따라서 Closed loop control을 통해서 얻을 수 있는 이점을 얻게 된다.
- reproducible한 dataset과 standard object set을 선정하였다.
Etc
Centre Third
농구 코드처럼 중간에 있는 공간을 Centre Third라고 흔히 부릅니다.
아래 사진 참고.

model’s Topology
보통 model architecture 대신에 topology라고 쓰기도 한다.
Open loop Robot & Closed loop Robot
Open loop system에서는 current state를 기준으로만 actuator의 제어량을 결정한다. 이를 Nonservo, Pick and Place 라고도 부른다.
system 제어량에 대한 feedback이 없으므로, signal이 가해지는 시간과 signal의 integrity(무결성)가 매우 중요하다.
따라서, robot의 이동량과 동작이 미리 결정되어있는 상황에서 적합한 제어 방식이다.

다른 제어 방식으로는 Closed loop system이 있다. current state와 feedback을 통하여 actuator의 제어량을 결정한다. 이를 Servo 방식이라고도 한다.
Servo란, Error Sensing feedback을 이용해서 다른 device를 제어하는 device를 일컫는다. 즉, 오차를 검출하고 제어에 사용하는 것이다.

antipodal grasp pose
양쪽에서 물체를 집는 것을 의미한다.

Adversarial Geometry
잡기 어려운 형상을 의미한다. 본 논문에서는 아래 왼쪽 그림을 의미한다.

'AI > Paper Review' 카테고리의 다른 글
| [Paper Review] EPS(Explicit Pseudo-pixel Supervision) 논문 리뷰 (0) | 2023.01.08 |
|---|---|
| [Paper Review] DeepLab V2 논문 리뷰 (0) | 2022.08.24 |
| [Paper Review] DeepLab V1 논문 리뷰 (0) | 2022.08.12 |
| [Paper Review] U-Net 논문 리뷰 (0) | 2022.07.28 |
| [Paper Review] SSD : Single Shot Multibox Detector 논문 리뷰 (0) | 2022.07.06 |