Introduction
기존 방법은 EKF나 optimization based method로 나뉜다.
여기서 optimization의 핵심은 full Bundle Adjustment (BA)이다. 이는 camera pose와 3D map을 동시에 최적화한다.
이런 optimization 방법은 여러 종류의 센서를 활용하기에 적합하다는 것이다.
For example, ORB-SLAM3 [5] supports monocular, stereo, RGB-D, and IMU sensors, and modern systems can support a variety of camera models [5, 27, 43, 6].
하지만 여전히 feature tracking을 실패하거나, drift error를 완전히 해결하지 못하는 문제를 보였다. 이는 robustness 문제로 보인다.
이를 위해 기존 방법들은 학습된 feature로 correspondence를 만들어 활용하려고 하거나, neural net의 representation을 활용하려고 하거나, 전통적인 방식의 optimization으로 문제를 해결하려고 했다고 한다. 기존 방법과는 다르게, DROID-SLAM에서는 딥러닝을 활용하여 SLAM의 약점을 보완하고자 한다.
이를 위해 DROID-SLAM은 “Differentiable Recurrent Optimization-Inspired Design” (DROID)와 optical flow를 활용한다.
Contribution은 다음과 같다.
- 성능 상승
- catastrophic failures 방지
- Generalization
RAFT와는 다르게 DROID-SLAM은 camera pose와 depth를 반복적으로 업데이트한다. long trajectory에 대응하기 위해서 인접한 두 프레임만 아니라 임의의 여러 프레임에 대해서 수행한다. 이를 통해 differentiable Dense Bundle Adjustment (DBA) layer 거쳐 camera poses 와 dense per-pixel depth를 업데이트 한다. 이를 통해 monocular setting을 활용할 수 있게 된다.

Related Work
Visual SLAM
indirect method : intermediate representation을 통해서 feature correspondence를 만들고 이를 통해 reprojection error를 만들어서 이를 최소화하는 방식으로 연산을 수행한다. 대표적으로 ORB-SLAM이 있겠다.
direct method : image를 활용해서 photometric loss를 정의하는 method를 direct method라고 한다. 이 경우 아무래도 정보량이 많아서 정확도가 올라가지만 대신에 속도가 느리다는 문제가 있다. 그래서 대체로 keyframe selection을 수행하는 듯
DROID-SLAM은 이 두 method의 중간 정도에 위치하는 method라고 한다.
Deep Learning in SLAM
또한 최근 연구부터 SLAM에 딥러닝을 활용하는 연구가 활발히 진행되었는데, feature detection/matching을 활용하는 연구도 있었고, computation graph를 gradient descent로 푸는 연구도 있었다. 하지만 대부분 인접한 몇 개의 프레임만 사용해서 SLAM을 수행한다는 문제가 있었다.
DROID-SLAM은 recurrent NN을 활용하여 Global Bundle Adjustment를 유지한다.
Approach
기본은 monocular이고, 이후 RGBD 이미지에 대해서도 일반화 한다고 한다. 기본적인 변수는 다음과 같다.
ordered collection of images { 𝐈 𝑡 }
camera pose 𝐆 𝑡 ∈ 𝑆 𝐸 ( 3 )
inverse depth 𝐝 𝑡 ∈ ℝ + 𝐻 × 𝑊 .
camera pose와 inverse depth는 iterative update 된다.
frame-graph (𝒱,ℰ) 를 활용하여 frame 간의 co-visibility를 표현한다. (𝑖,𝑗)∈ℰ 는 image 𝐈𝑖 and 𝐈𝑗 간에 겹치는 fields of view가 있다는 의미가 되고, 이 정보는 SLAM 과정에서 지속적으로 update된다.
Feature Extraction and Correlation
optical flow 등의 중요한 부분은 RAFT라는 연구에서 가지고 왔다고 한다.
우선 input image의 feature를 추출한다. RAFT에서 처럼 두 개의 network를 사용한다. feature network는 correlation volume를 만들고, context network는 이후의 각 operator에 투입되는데 사용된다. 아래는 RAFT의 architecture이다. 최종적으로 optical flow를 만들어낸다.

각 edge에 해당하는 frame graph마다, 다음과 같이 correlation volume을 계산한다. 이를 통해 correlation pyramid를 만들 것이다.

lookup operator를 정의한다. correlation volume를 radius로 인덱싱한다. 입력은 HW grid가 들어가고 이를 interpolate해서 값을 내놓는다. 각 피라미드 마다 이 연산이 적용되고 concatenate해서 마지막 결과가 나온다.

이 과정까지는 RAFT와 동일하다.
자세한 것은 이분 블로그를 확인하면 좋을 것이다.
[Optical Flow/Paper Review] RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
Intro 오늘은 ECCV 2020 Best Paper Award를 수상한 RAFT: Recurrent All-Pairs Field Transforms for Optical Flow를 같이 살펴보겠습니다. 원래 2022년 중순쯤에 포스팅을 준비했었는데, 현실에 치여 이제야 포스팅을 준비
searching-fundamental.tistory.com
[CV/Optical Flow] FlowNet(ICCV 2015) (tistory.com)
[CV/Optical Flow] FlowNet(ICCV 2015)
Intro 이전 포스트들을 통해 Handcrafted Optical Flow 기법들에 대해 알아보았습니다. 이제는 Deep Learning을 통해 Optical Flow를 구하는 연구들에 대해 다룰 예정입니다. 그 시작은 ICCV 2015에서 발표된 FlowNet
searching-fundamental.tistory.com
아래는 feature/context encoder의 구조이다.

Update Operator

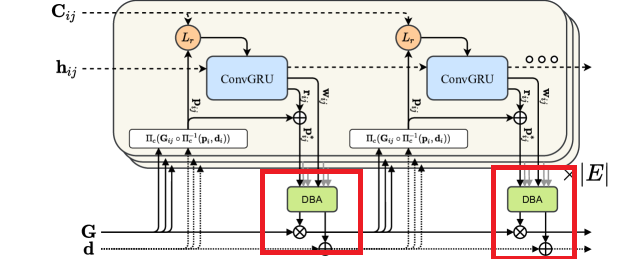
update operator로 convolutional GRU를 활용한다. hidden state 𝐡와 pose update Δ𝝃(𝑘), depth update Δ𝐝(𝑘)를 수행한다. 이 과정에서 retraction on SE3 manifold를 수행한다고 하는데 무엇인지는 나도 모른다. Lie group 관련된 얘기인듯.
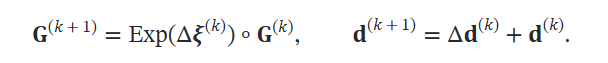
그 결과 다음과 같이 수렴하기를 바라는 것이다.
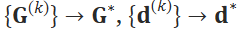
이 과정이 바로 표시한 부분
여기서 correspondence를 예측하기 위해서 pose와 depth를 활용한다. pixel coordinate 𝐩𝑖∈ℝ𝐻×𝑊×2 에 대해서, 다음과 같이 dense correspondence field를 만든다.
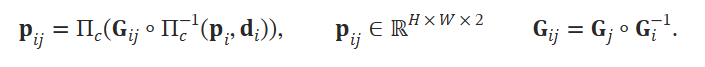
이는 각 edge에 대해서 수행된다. Π𝑐는 카메라 파라미터로 3D → 2D projection을 수행하는 것을 의미한다. 그의 역수는 2D → 3D projection을 의미한다. 아래에도 표시한 부분이다.
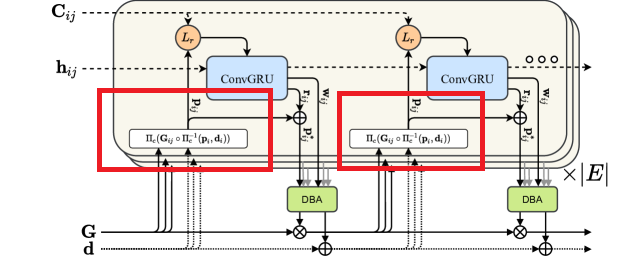
ConvGRU의 input으로 correlation volume을 넣고 optical flow를 구한다. 그리고 이를 𝐩𝑖𝑗−𝐩𝑗로 활용한다. 그리고 residual conection을 통해서 이전에 구한 BA solutiond을 concatenate해서 다시 활용한다. 이게 바로 아래 부분이다.
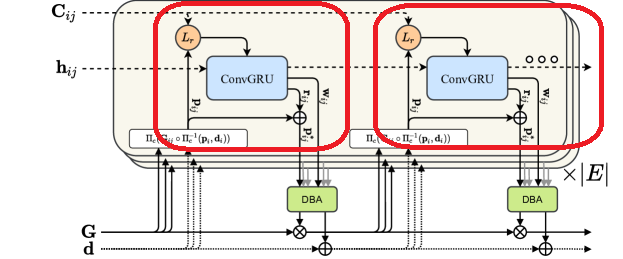
여기서 hidden state는 global context를 저장한다. 이를 통해 큰 변위 등에 대해서 SLAM 모델이 강건해지도록 유도한다. 여기서 revision flow field와 confidence map을 구해서 다음과 같이 correspondence field를 개선한다.
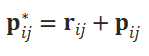
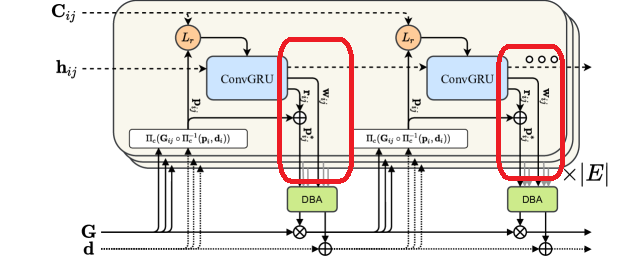
여기서 모든 hidden state를 pool해서 pixelwise damping factor 𝜆를 구한다. 그리고 pool한 hidden state를 또 활용해서 inverse depth estimate가 가능한 8x8 mask로 만든다.
Dense Bundle Adjustment Layer (DBA)는 optical flow set을 pose와 pixelwise depth로 업데이트한다. 이를 위해 다음과 같은 cost function을 정의한다.
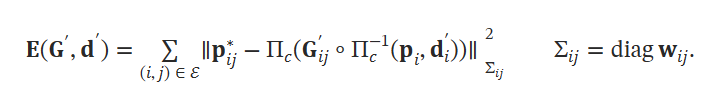
이 식을 통해서 Δ𝝃(𝑘), Δ𝐝(𝑘)를 구하려고 하는 것이다. 이를 위해 Gauss-Netwon Method를 사용한다. 여기서 depth variable이 하나라서, 다음과 같은 block diagonal structure를 구성할 수 있다고 한다.(???) 이를 위해 Schur complement를 활용하면 pixelwise dampoing factor 𝜆를 활용하면 다음과 같이 풀이할 수 있다고 한다.
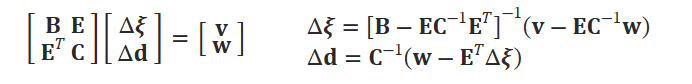
이 layer를 DBA layer라고 하고 이는 학습단계에서도 backpropagation이 가능하다고 한다.
Training
- Gauge Freedom을 제거하기 위하여 두번째 프레임 까지는 GT pose를 활용한다고 한다.
- first pose는 6 DOF gauage freedom을 제거한다.
- second pose는 scale freedom을 제거한다.
- 각 training moduel 은 7 프레임 씩 받는다.
- 𝑁𝑖×𝑁𝑖 사이즈의 각 프레임별 distance matrix를 만든다.
- 여기서 오류를 보완하기 위해서 distance matrix를 sampling해서 video를 생성하여 활용한다.
- pose loss와 flow loss를 활용한다.
- flow loss는 두 인접 프레임을 활용한다. optical flow를 예측한 depth, pose로 구하고 ground truth depth, pose로 구한 flow와 L2 loss를 둔다.
- pose loss는 GT pose와 predicted pose 사이에 다음 식으로 정의한다. 이 부분은 학습에 따라 exponenetial increasing weight를 둔다.
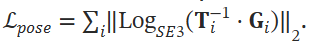
SLAM System
The frontend thread는 프레임을 새로 받고, feature extraction을 하고, keyframe을 정하고, local BA를 수행한다.
The backend thread 는 전체 keyframe에 대해서 global BA를 수행한다.
- Initialization : 총 12개의 프레임을 활용한다. 16px 이상의 optical flow 차이가 나면 그 프레임을 저장한다. 3 timestep 내에 있는 프레임으로 edge를 형성하고, update operator를 10번 실행한다.
- Frontend : video stream을 받아서 keyframe, frame graph를 형성한다. 그리고 local BA를 수행한다. pose는 linear motion model을 통해 초기화 되고, 이후 update operator를 통해 pose와 depth가 업데이트 된다. 이후에는 keyframe을 제거하는데, 이는 average optical flow magnitude를 계산해서 redundant frame을 선정하는 방식으로 수행된다. 만약 선정이 어렵다면 가장 오래된 frame을 골라 제거한다.
- Backend : global BA를 전체 keyframe에 대해서 수행한다. frame graph를 optical flow를 통해 다시 만든다. 이를 𝑁×𝑁 distance matrix로 표현한다.
- Stereo and RGB-D : RGBD나 Stereo camera로의 확장은 단순히 depth loss를 추가함으로써 수행된다. 인접한 keyframe 에 edge를 생성하는데, 여기서 distance matrix를 활용한다. 여기서 keyframe의 edge끼리 distance가 2이내로 유지되도록 제한한다. 여기서 Chebyshev distance를 활용한다. 이후 전체 frame에 대해서 update operator를 수행한다.
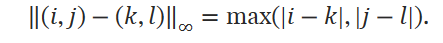
Experiments
학습은 3090 4개로 1주가 걸린다고 한다. 너무 오래 걸리는 거 아닌가?
Qualitative Results는 다음과 같다.



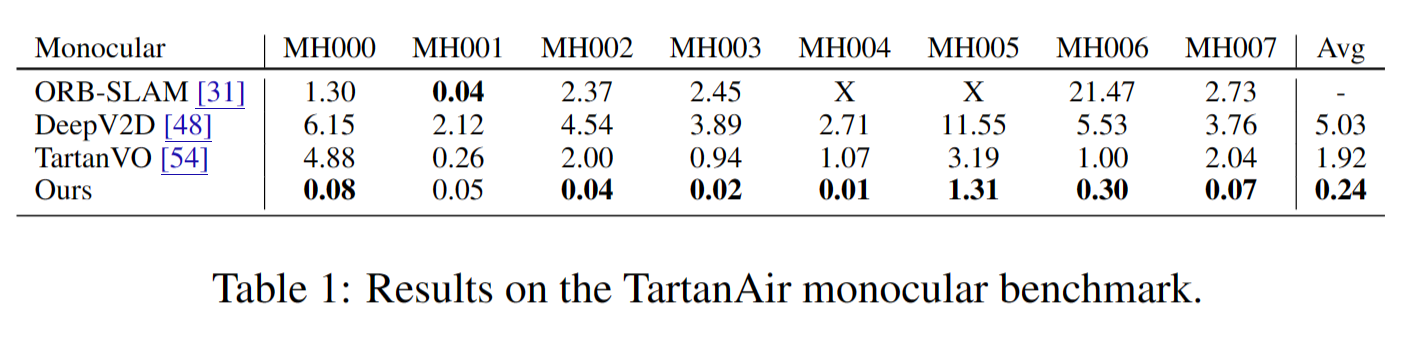
다음은 TartanAir monocular dataset에서 실험한 결과이다. 대체로 성능이 더 좋은것을 볼 수 있다.

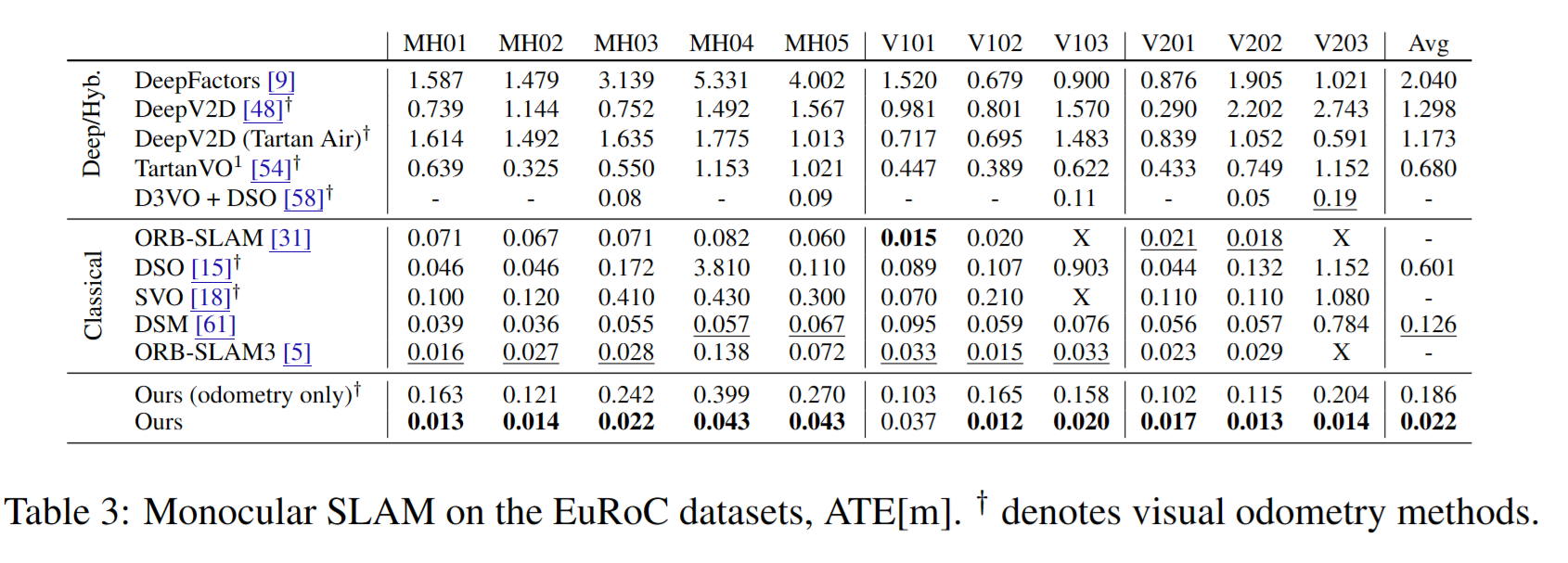
다음은 TartanAir monocular dataset에서 학습한 모델을 EuRoC dataset에서 그대로 사용했을 때의 성능이다. generalization 성능이 뛰어나다는 것을 알 수 있다.
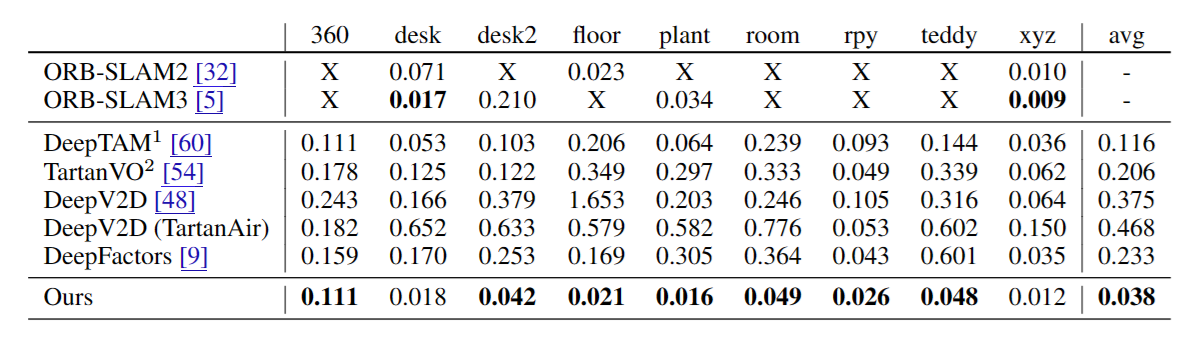
다음은 noise가 많은 TUM-RGBD dataset에서의 성능이다. 여기선 RGBD를 활용해서 학습을 진행했다.
abalation study는 따로 없어서 아쉬웠다. 그리고 이번에도 outdoor scene에서의 성능은 없었다.