[논문리뷰] AllWeatherNet:Unified Image Enhancement for Autonomous Driving under Adverse Weather and Lowlight-conditions
AllWeatherNet:Unified Image Enhancement for Autonomous Driving under Adverse Weather and Lowlight-conditions
Adverse conditions like snow, rain, nighttime, and fog, pose challenges for autonomous driving perception systems. Existing methods have limited effectiveness in improving essential computer vision tasks, such as semantic segmentation, and often focus on o
arxiv.org
Keypoints
- Autonomous driving scene을 타겟. Image enhancement를 수행하고자 한다.
- low-light enhancement, overcasting, adverse weather corruption을 한 번에 해결하는 Scaled Illumination-aware Attention Mechanism을 도입한 framework 제안
- 기존 방법들이 scene-level enhancement 과정에서 발생하는 artifact를 object-level/texture-level feature를 도입하여 해결
Details
source-target pair가 있는 데이터셋에서 학습한다. Enhancement 결과와 target domain의 결과 사이에 대해서 adversarial loss를 가해서 generator를 학습하는 것이 제안된 방법의 기본틀이다.

generator에 입력하여 enhancement에 활용하기 위한 attention을 제안한다.
pixel intensity를 기반으로하는데 다음과 같이 식을 조작한다. 왜 저렇게 하는지는 나도 잘 모르겠다.


Discriminator의 동작은 단순히 scene level에서만 하는 것이 아니라, object detector를 하나 도입해서 multi-scale에서 수행한다.

이 과정에서 object를 잘못 잡을 수 있으므로, 처음 제안 받은 detection region에서 여러 candidate를 구해서 가장 좋은 score의 region을 찾고 이에 대해 object-level matching이 실행되도록 한다.


각 level에 따라 따로 LSGAN loss를 부여한다.

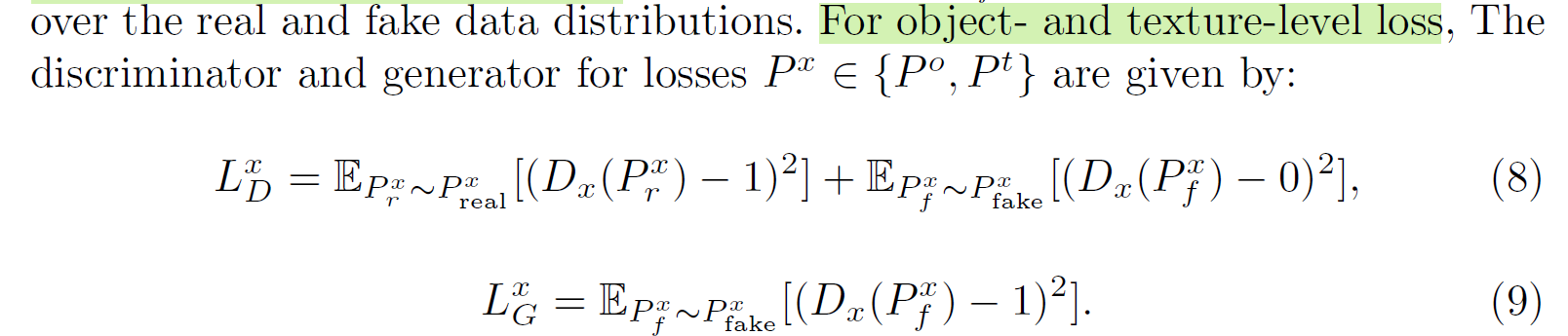
Experiments
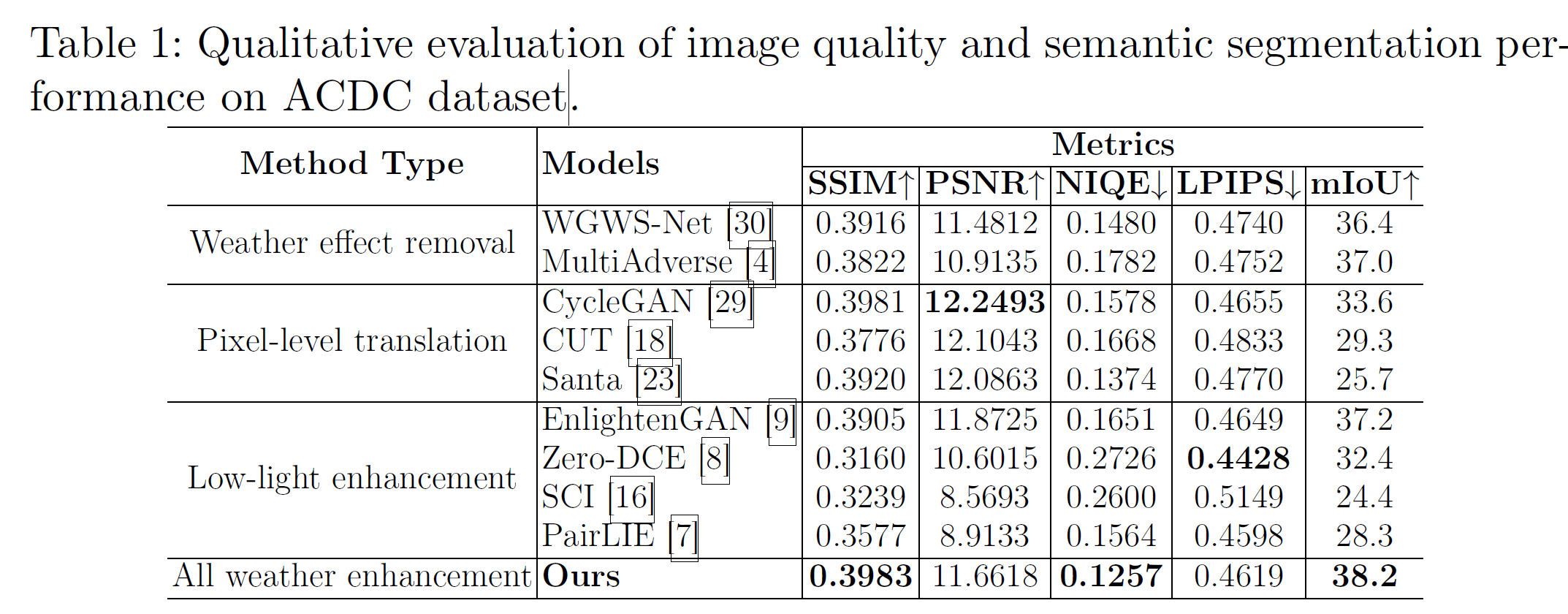
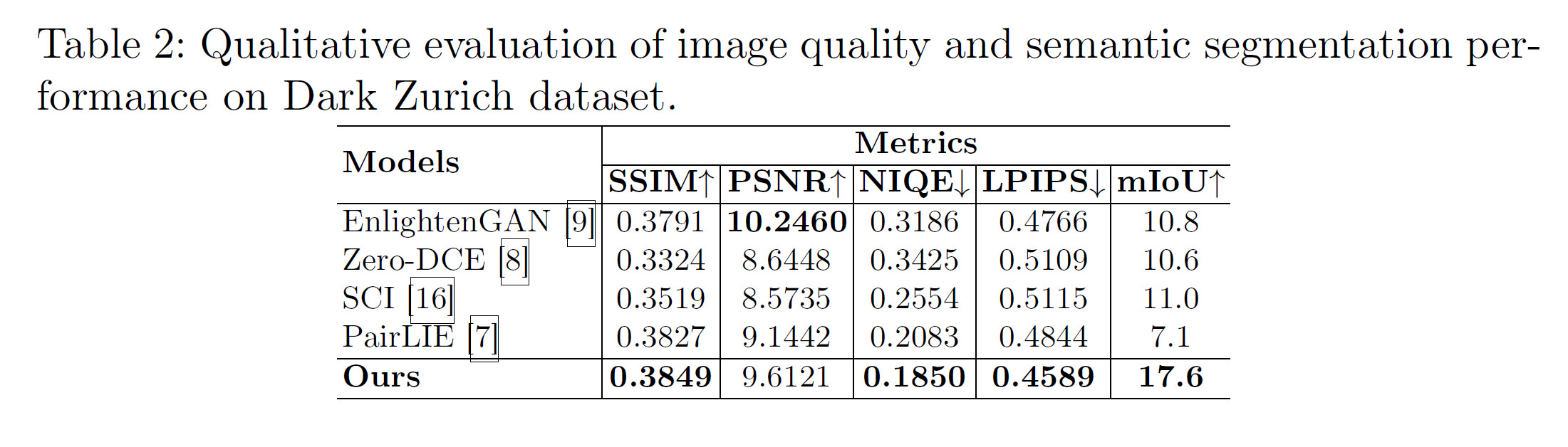
Qualitative는 잘 나오긴 했으나, 일정 영역을 넘어가면 눈으로는 무엇이 더 나은 것인지 도저히 판별할 수가 없다.

Segmentation에는 가장 도움이 되는 결과가 나왔다. SSIM, PSNR 따위가 높은 것보다 훨씬 유용한 결과...
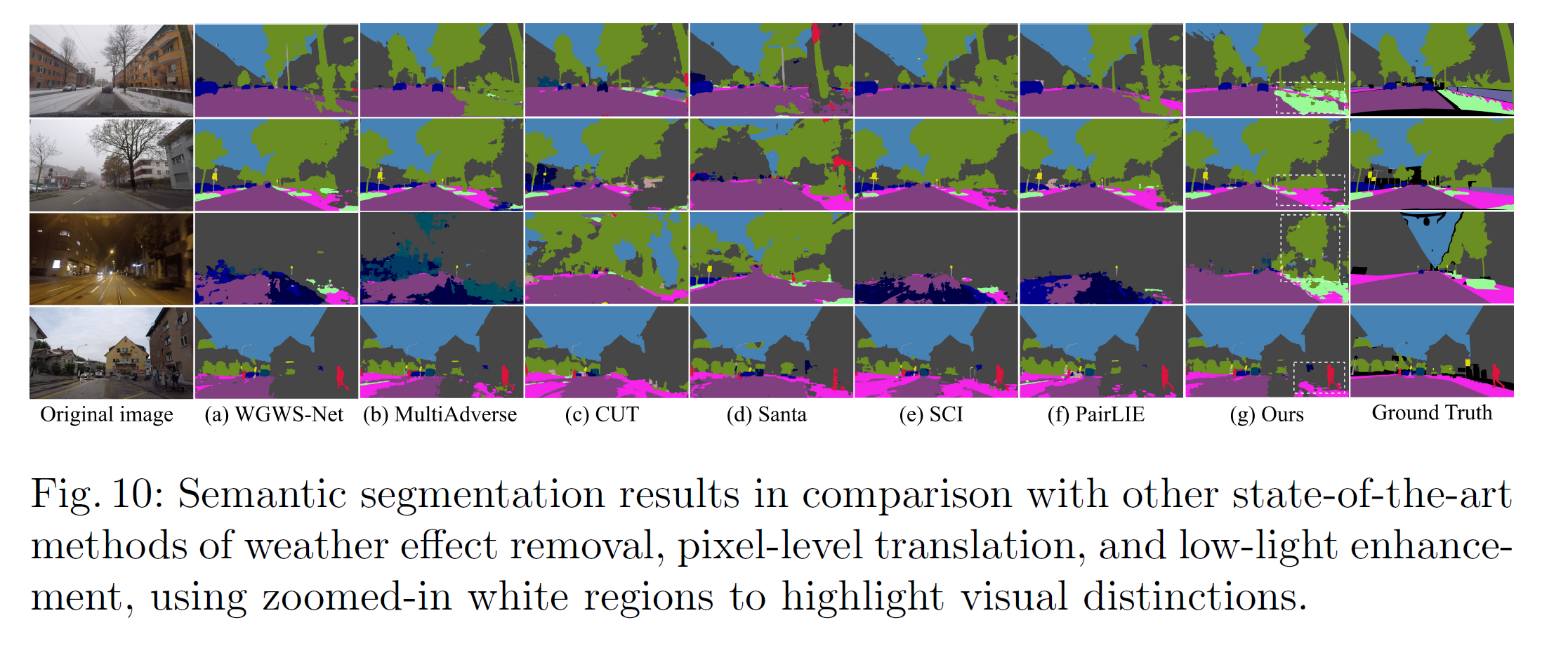
Naive하게 illumination으로 구한 attention보다, 제안한 attention이 더 좋다고 주장한다. artifact가 더 적게 나온다고.
